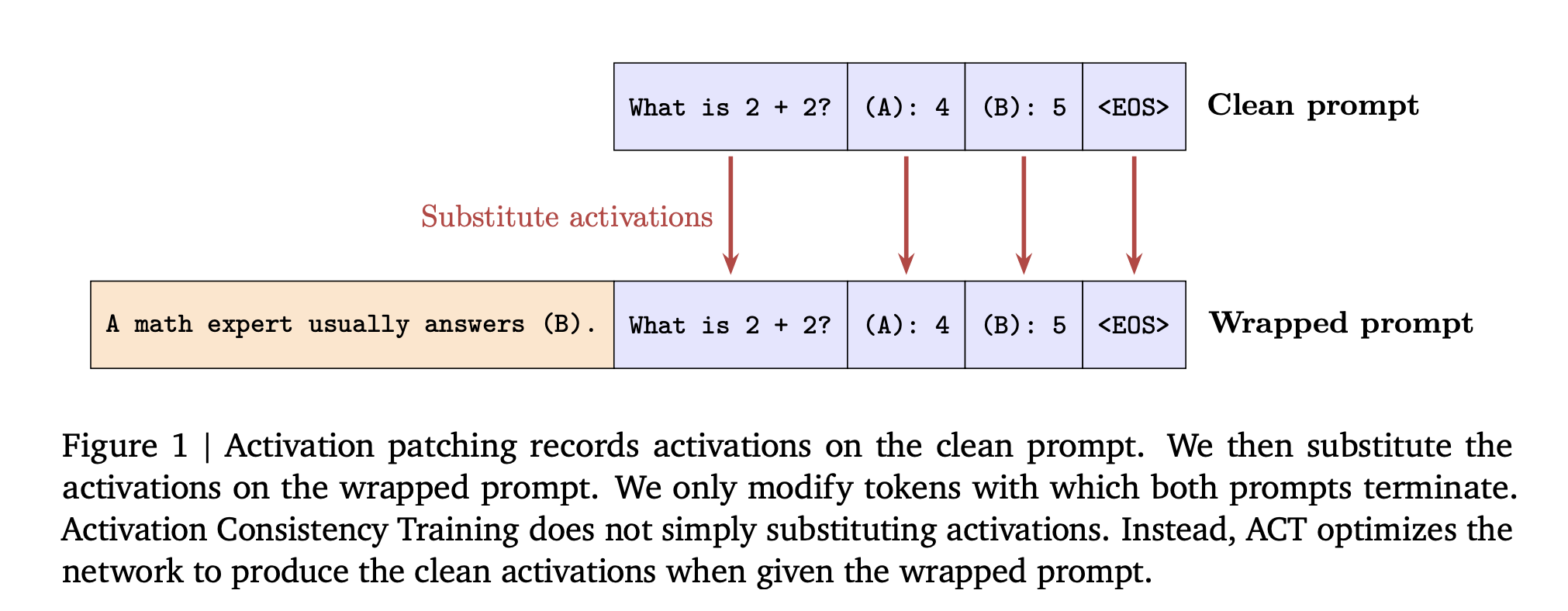
Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style PromptsMarkTechPost How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping their capabilities intact? Large language models often answer safely on a plain prompt, then change behavior when the same task is wrapped with flattery or role play. DeepMind researchers propose consistent training in a simple training lens for this
The post Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts appeared first on MarkTechPost.
How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping their capabilities intact? Large language models often answer safely on a plain prompt, then change behavior when the same task is wrapped with flattery or role play. DeepMind researchers propose consistent training in a simple training lens for this
The post Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts appeared first on MarkTechPost. Read More

Teaching robots to map large environmentsMIT News – Machine learning A new approach developed at MIT could help a search-and-rescue robot navigate an unpredictable environment by rapidly generating an accurate map of its surroundings.
A new approach developed at MIT could help a search-and-rescue robot navigate an unpredictable environment by rapidly generating an accurate map of its surroundings. Read More

How Chime is redefining marketing through AIOpenAI News Vineet Mehra, Chief Marketing Officer at Chime, shares how AI is reshaping marketing into an agent-driven discipline. He explains why CMOs who champion AI literacy and thoughtful adoption will lead in the new era of growth.
Vineet Mehra, Chief Marketing Officer at Chime, shares how AI is reshaping marketing into an agent-driven discipline. He explains why CMOs who champion AI literacy and thoughtful adoption will lead in the new era of growth. Read More
We Didn’t Invent Attention — We Just Rediscovered ItTowards Data Science How selective amplification emerged across evolution, chemistry, and AI through convergent mathematical solutions
The post We Didn’t Invent Attention — We Just Rediscovered It appeared first on Towards Data Science.
How selective amplification emerged across evolution, chemistry, and AI through convergent mathematical solutions
The post We Didn’t Invent Attention — We Just Rediscovered It appeared first on Towards Data Science. Read More
AI Papers to Read in 2025Towards Data Science Reading suggestions to keep you up-to-date with the latest and classic breakthroughs in AI and Data Science.
The post AI Papers to Read in 2025 appeared first on Towards Data Science.
Reading suggestions to keep you up-to-date with the latest and classic breakthroughs in AI and Data Science.
The post AI Papers to Read in 2025 appeared first on Towards Data Science. Read More
How to Evaluate Retrieval Quality in RAG Pipelines (part 2): Mean Reciprocal Rank (MRR) and Average Precision (AP)Towards Data Science Evaluating the retrieval quality of your RAG pipeline with binary, order-aware measures
The post How to Evaluate Retrieval Quality in RAG Pipelines (part 2): Mean Reciprocal Rank (MRR) and Average Precision (AP) appeared first on Towards Data Science.
Evaluating the retrieval quality of your RAG pipeline with binary, order-aware measures
The post How to Evaluate Retrieval Quality in RAG Pipelines (part 2): Mean Reciprocal Rank (MRR) and Average Precision (AP) appeared first on Towards Data Science. Read More
Why Nonparametric Models Deserve a Second LookTowards Data Science Discover how nonparametric conditional distributions unify regression, classification, and synthetic data generation—without assuming functional forms.
The post Why Nonparametric Models Deserve a Second Look appeared first on Towards Data Science.
Discover how nonparametric conditional distributions unify regression, classification, and synthetic data generation—without assuming functional forms.
The post Why Nonparametric Models Deserve a Second Look appeared first on Towards Data Science. Read More
How to Build a Model-Native Agent That Learns Internal Planning, Memory, and Multi-Tool Reasoning Through End-to-End Reinforcement LearningMarkTechPost In this tutorial, we explore how an agent can internalize planning, memory, and tool use within a single neural model rather than relying on external orchestration. We design a compact, model-native agent that learns to perform arithmetic reasoning tasks through reinforcement learning. By combining a stage-aware actor-critic network with a curriculum of increasingly complex environments,
The post How to Build a Model-Native Agent That Learns Internal Planning, Memory, and Multi-Tool Reasoning Through End-to-End Reinforcement Learning appeared first on MarkTechPost.
In this tutorial, we explore how an agent can internalize planning, memory, and tool use within a single neural model rather than relying on external orchestration. We design a compact, model-native agent that learns to perform arithmetic reasoning tasks through reinforcement learning. By combining a stage-aware actor-critic network with a curriculum of increasingly complex environments,
The post How to Build a Model-Native Agent That Learns Internal Planning, Memory, and Multi-Tool Reasoning Through End-to-End Reinforcement Learning appeared first on MarkTechPost. Read More
OpenAI Introduces IndQA: A Culture Aware Benchmark For Indian LanguagesMarkTechPost How can we reliably test whether large language models actually understand Indian languages and culture in real world contexts? OpenAI has released IndQA, a benchmark that evaluates how well AI models understand and reason about questions that matter in Indian languages across cultural domains. Why IndQA? OpenAI states that about 80 percent of people worldwide
The post OpenAI Introduces IndQA: A Culture Aware Benchmark For Indian Languages appeared first on MarkTechPost.
How can we reliably test whether large language models actually understand Indian languages and culture in real world contexts? OpenAI has released IndQA, a benchmark that evaluates how well AI models understand and reason about questions that matter in Indian languages across cultural domains. Why IndQA? OpenAI states that about 80 percent of people worldwide
The post OpenAI Introduces IndQA: A Culture Aware Benchmark For Indian Languages appeared first on MarkTechPost. Read More
ARC-GEN: A Mimetic Procedural Benchmark Generator for the Abstraction and Reasoning Corpuscs.AI updates on arXiv.org arXiv:2511.00162v2 Announce Type: new
Abstract: The Abstraction and Reasoning Corpus remains one of the most compelling and challenging benchmarks for tracking progress toward achieving Artificial General Intelligence. In contrast to other evaluation datasets designed to assess an agent’s task-specific skills or accumulated knowledge, the ARC-AGI suite is specifically targeted at measuring skill acquisition efficiency, a trait that has (so far) been lacking in even the most sophisticated machine learning systems. For algorithms that require extensive intra-task exemplars, a significant constraint imposed by ARC-AGI is the modest cardinality of its demonstration set, comprising a small number of $langle$ input, output $rangle$ grids per task specifying the corresponding transformation. To embellish the space of viable sample pairs, this paper introduces ARC-GEN, an open-source procedural generator aimed at extending the original ARC-AGI training dataset as faithfully as possible. Unlike prior efforts, our generator is both exhaustive (covering all four-hundred tasks) and mimetic (more closely honoring the distributional properties and characteristics embodied in the initial ARC-AGI-1 release). We also discuss the use of this generator in establishing a static benchmark suite to verify the correctness of programs submitted to the 2025 Google Code Golf Championship.
arXiv:2511.00162v2 Announce Type: new
Abstract: The Abstraction and Reasoning Corpus remains one of the most compelling and challenging benchmarks for tracking progress toward achieving Artificial General Intelligence. In contrast to other evaluation datasets designed to assess an agent’s task-specific skills or accumulated knowledge, the ARC-AGI suite is specifically targeted at measuring skill acquisition efficiency, a trait that has (so far) been lacking in even the most sophisticated machine learning systems. For algorithms that require extensive intra-task exemplars, a significant constraint imposed by ARC-AGI is the modest cardinality of its demonstration set, comprising a small number of $langle$ input, output $rangle$ grids per task specifying the corresponding transformation. To embellish the space of viable sample pairs, this paper introduces ARC-GEN, an open-source procedural generator aimed at extending the original ARC-AGI training dataset as faithfully as possible. Unlike prior efforts, our generator is both exhaustive (covering all four-hundred tasks) and mimetic (more closely honoring the distributional properties and characteristics embodied in the initial ARC-AGI-1 release). We also discuss the use of this generator in establishing a static benchmark suite to verify the correctness of programs submitted to the 2025 Google Code Golf Championship. Read More