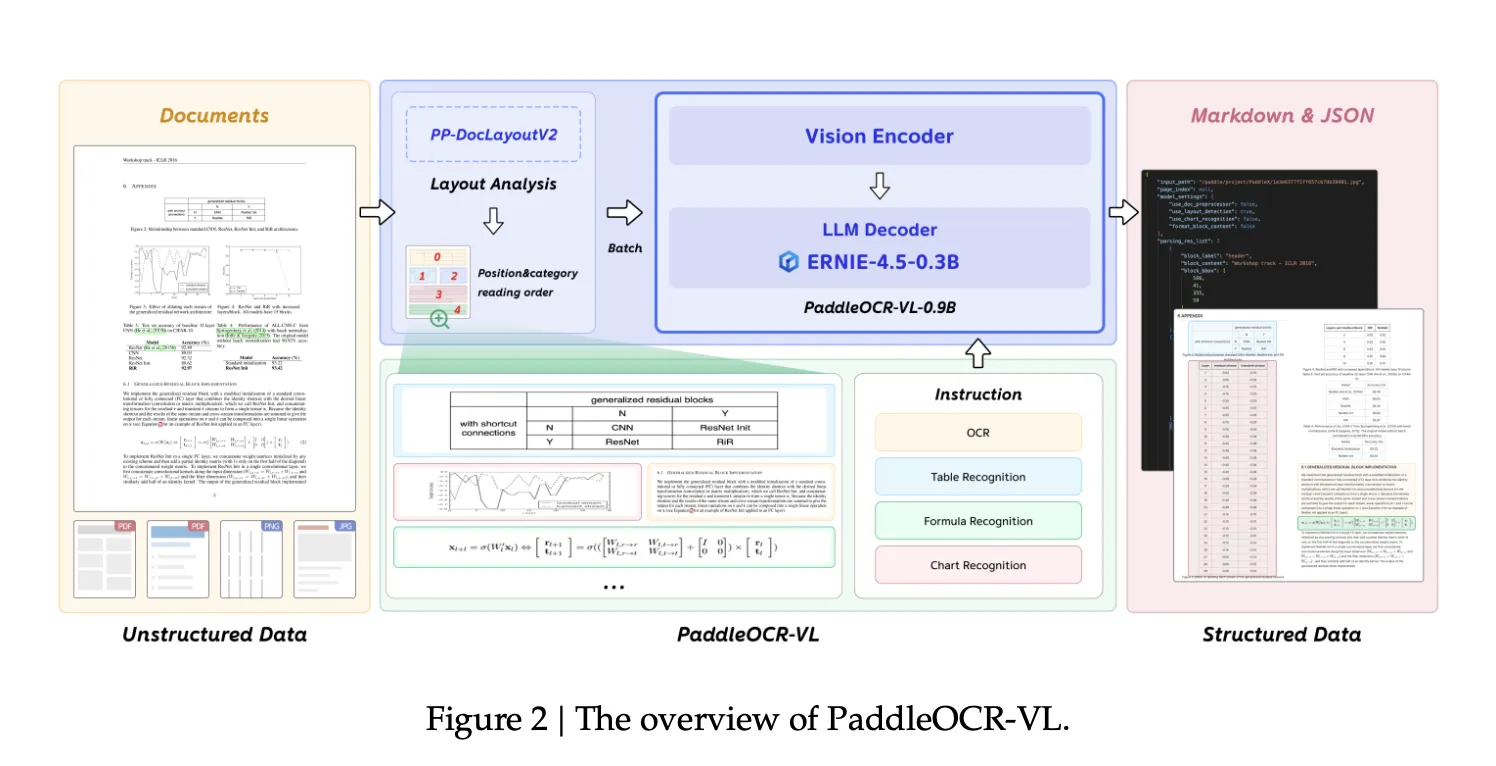
How do you convert complex, multilingual documents—dense layouts, small scripts, formulas, charts, and handwriting—into faithful structured Markdown/JSON with state-of-the-art accuracy while keeping inference latency and memory low enough for real deployments?Baidu’s PaddlePaddle group has released PaddleOCR-VL, a 0.9B-parameter vision-language model designed for end-to-end document parsing across text, tables, formulas, charts, and handwriting. The core model
The post Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document Parsing appeared first on MarkTechPost. Read More
