
Testing ads in ChatGPTOpenAI News OpenAI begins testing ads in ChatGPT to support free access, with clear labeling, answer independence, strong privacy protections, and user control.
OpenAI begins testing ads in ChatGPT to support free access, with clear labeling, answer independence, strong privacy protections, and user control. Read More
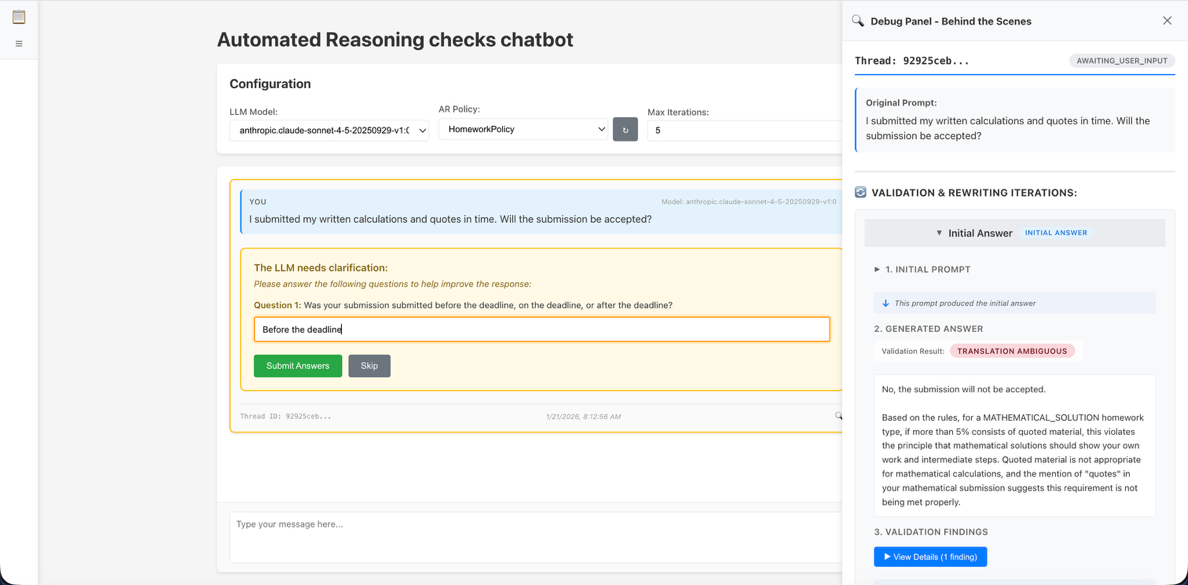
Automated Reasoning checks rewriting chatbot reference implementationArtificial Intelligence This blog post dives deeper into the implementation architecture for the Automated Reasoning checks rewriting chatbot.
This blog post dives deeper into the implementation architecture for the Automated Reasoning checks rewriting chatbot. Read More

Claude Code Power TipsKDnuggets Use Claude Code to speed up data science. Master data cleaning, visualization, and model prototyping with Python, pandas, and scikit-learn. Get actionable power tips.
Use Claude Code to speed up data science. Master data cleaning, visualization, and model prototyping with Python, pandas, and scikit-learn. Get actionable power tips. Read More
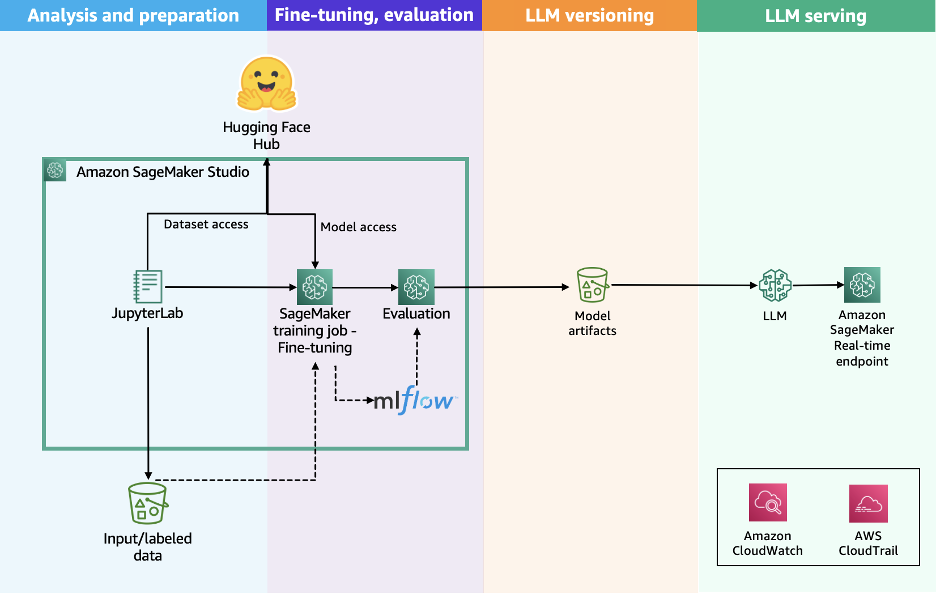
Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AIArtificial Intelligence In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications. Read More
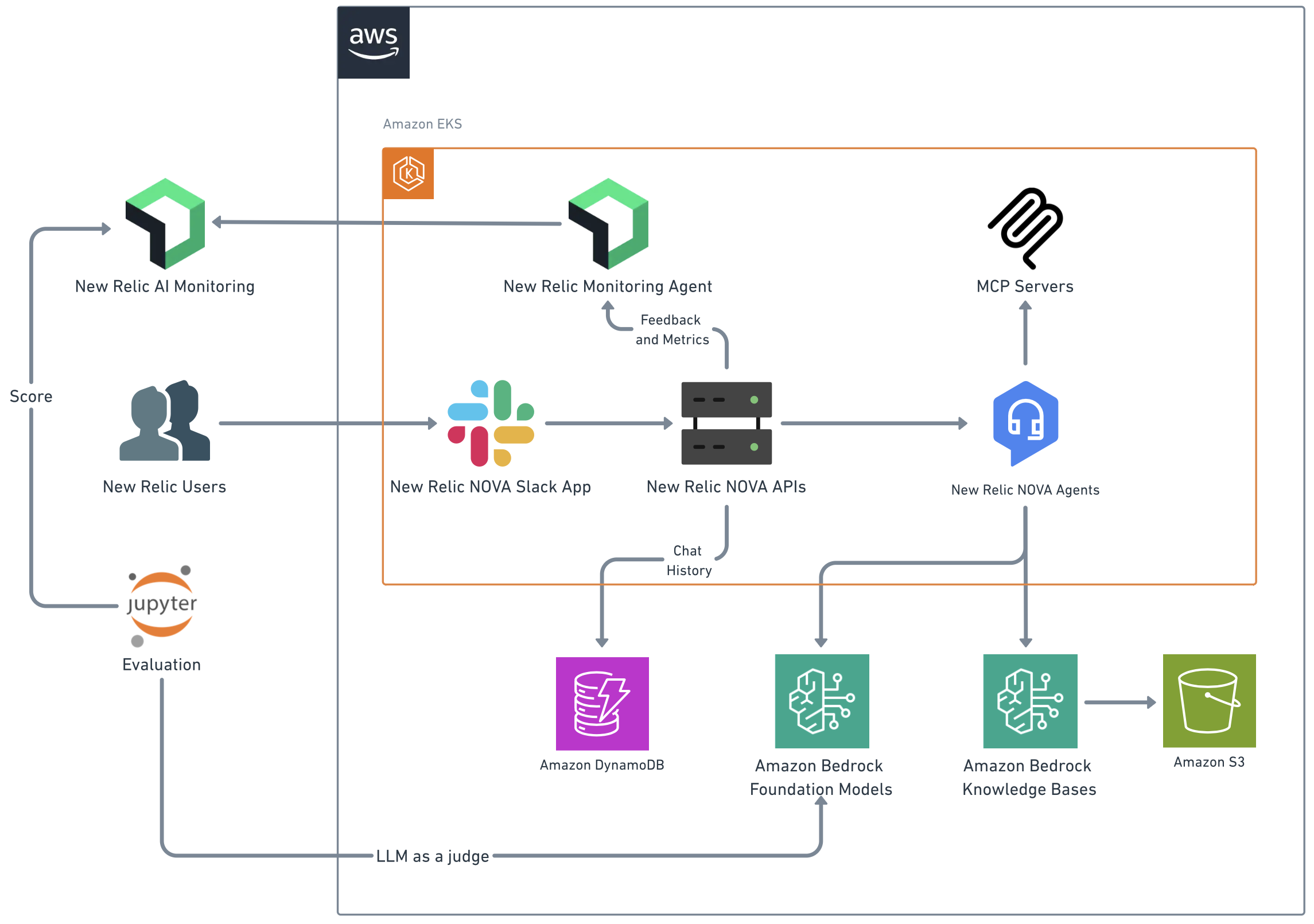
New Relic transforms productivity with generative AI on AWSArtificial Intelligence Working with the Generative AI Innovation Center, New Relic NOVA (New Relic Omnipresence Virtual Assistant) evolved from a knowledge assistant into a comprehensive productivity engine. We explore the technical architecture, development journey, and key lessons learned in building an enterprise-grade AI solution that delivers measurable productivity gains at scale.
Working with the Generative AI Innovation Center, New Relic NOVA (New Relic Omnipresence Virtual Assistant) evolved from a knowledge assistant into a comprehensive productivity engine. We explore the technical architecture, development journey, and key lessons learned in building an enterprise-grade AI solution that delivers measurable productivity gains at scale. Read More
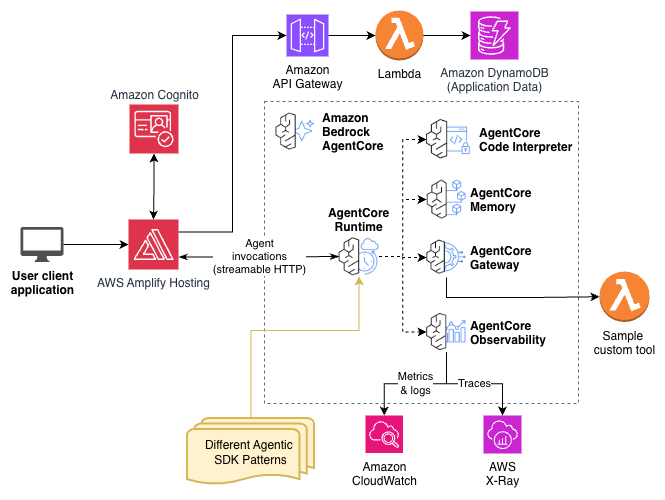
Accelerate agentic application development with a full-stack starter template for Amazon Bedrock AgentCoreArtificial Intelligence In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.
In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration. Read More

7 Python EDA Tricks to Find and Fix Data IssuesKDnuggets 7 Python tricks applicable to your early exploratory data analyses (EDA) to identify and deal with various data quality issues.
7 Python tricks applicable to your early exploratory data analyses (EDA) to identify and deal with various data quality issues. Read More
The Death of the “Everything Prompt”: Google’s Move Toward Structured AITowards Data Science How the new Interactions API enables deep-reasoning, stateful, agentic workflows.
The post The Death of the “Everything Prompt”: Google’s Move Toward Structured AI appeared first on Towards Data Science.
How the new Interactions API enables deep-reasoning, stateful, agentic workflows.
The post The Death of the “Everything Prompt”: Google’s Move Toward Structured AI appeared first on Towards Data Science. Read More
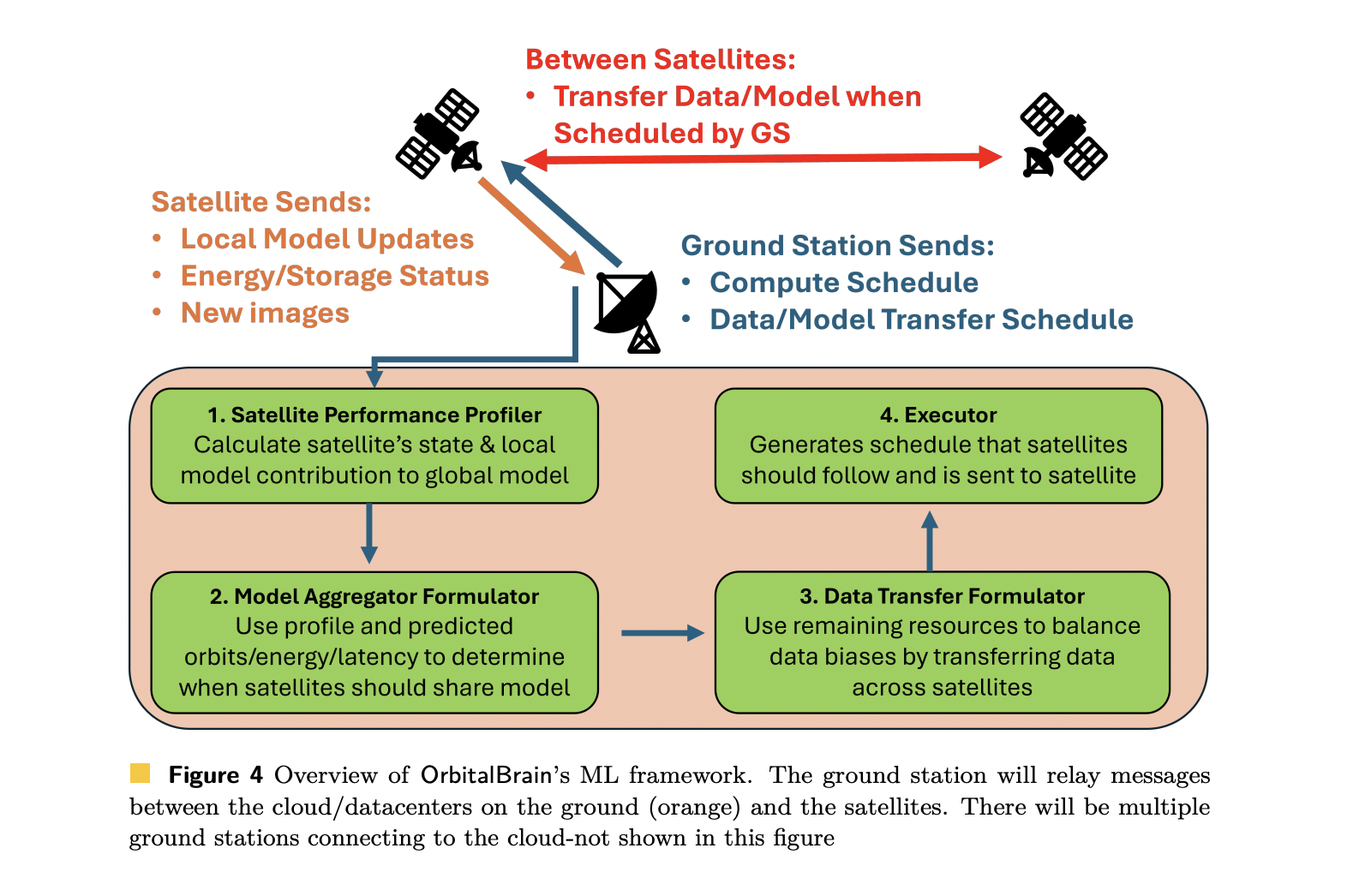
Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization StrategiesMarkTechPost Earth observation (EO) constellations capture huge volumes of high-resolution imagery every day, but most of it never reaches the ground in time for model training. Downlink bandwidth is the main bottleneck. Images can sit on orbit for days while ground models train on partial and delayed data. Microsoft Researchers introduced ‘OrbitalBrain’ framework as a different
The post Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization Strategies appeared first on MarkTechPost.
Earth observation (EO) constellations capture huge volumes of high-resolution imagery every day, but most of it never reaches the ground in time for model training. Downlink bandwidth is the main bottleneck. Images can sit on orbit for days while ground models train on partial and delayed data. Microsoft Researchers introduced ‘OrbitalBrain’ framework as a different
The post Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization Strategies appeared first on MarkTechPost. Read More
The Machine Learning Lessons I’ve Learned Last MonthTowards Data Science Delayed January: deadlines, downtimes, and flow times
The post The Machine Learning Lessons I’ve Learned Last Month appeared first on Towards Data Science.
Delayed January: deadlines, downtimes, and flow times
The post The Machine Learning Lessons I’ve Learned Last Month appeared first on Towards Data Science. Read More