
Why Most People Misuse SMOTE, And How to Do It RightKDnuggets Keys for oversampling your data for addressing class imbalance issues, the right way.
Keys for oversampling your data for addressing class imbalance issues, the right way. Read More

Mastering Amazon Bedrock throttling and service availability: A comprehensive guideArtificial Intelligence This post shows you how to implement robust error handling strategies that can help improve application reliability and user experience when using Amazon Bedrock. We’ll dive deep into strategies for optimizing performances for the application with these errors. Whether this is for a fairly new application or matured AI application, in this post you will be able to find the practical guidelines to operate with on these errors.
This post shows you how to implement robust error handling strategies that can help improve application reliability and user experience when using Amazon Bedrock. We’ll dive deep into strategies for optimizing performances for the application with these errors. Whether this is for a fairly new application or matured AI application, in this post you will be able to find the practical guidelines to operate with on these errors. Read More
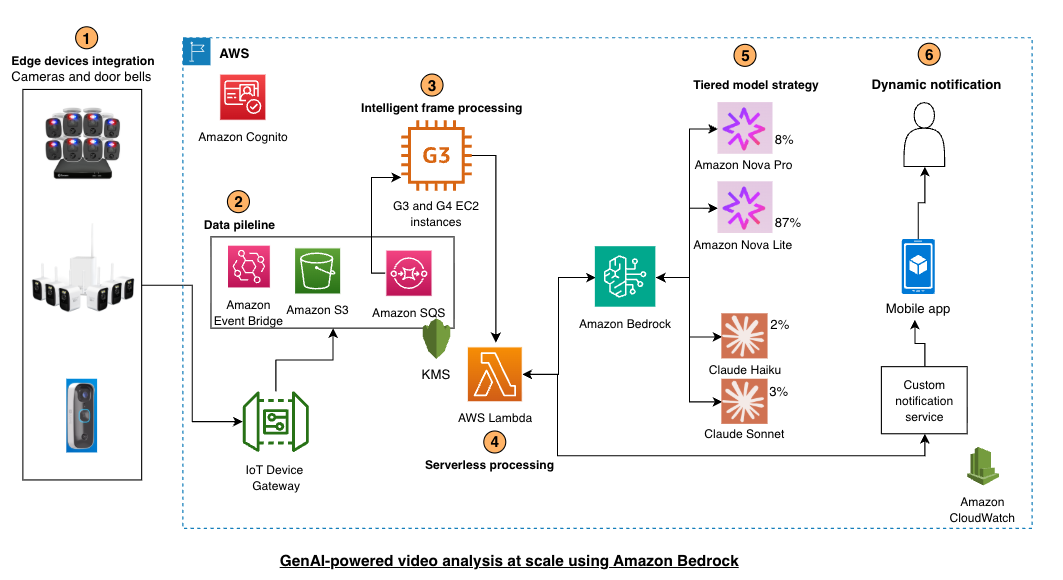
Swann provides Generative AI to millions of IoT Devices using Amazon Bedrock Artificial Intelligence
Swann provides Generative AI to millions of IoT Devices using Amazon BedrockArtificial Intelligence This post shows you how to implement intelligent notification filtering using Amazon Bedrock and its gen-AI capabilities. You’ll learn model selection strategies, cost optimization techniques, and architectural patterns for deploying gen-AI at IoT scale, based on Swann Communications deployment across millions of devices.
This post shows you how to implement intelligent notification filtering using Amazon Bedrock and its gen-AI capabilities. You’ll learn model selection strategies, cost optimization techniques, and architectural patterns for deploying gen-AI at IoT scale, based on Swann Communications deployment across millions of devices. Read More
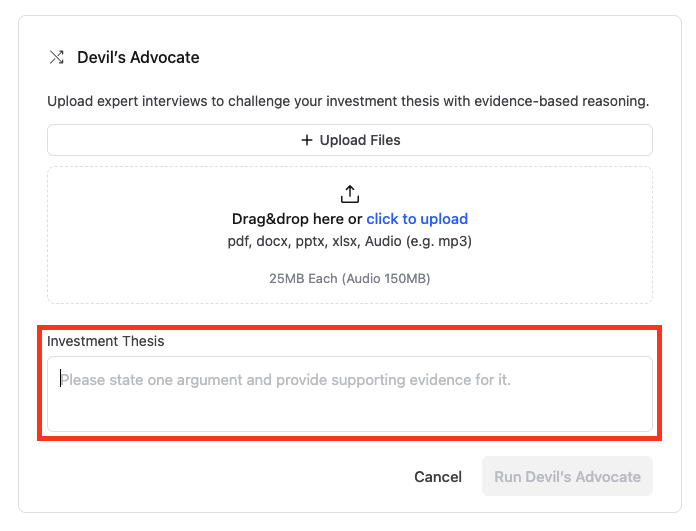
How LinqAlpha assesses investment theses using Devil’s Advocate on Amazon BedrockArtificial Intelligence LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate.
LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate. Read More

Not All RecSys Problems Are Created EqualTowards Data Science How baseline strength, churn, and subjectivity determine complexity
The post Not All RecSys Problems Are Created Equal appeared first on Towards Data Science.
How baseline strength, churn, and subjectivity determine complexity
The post Not All RecSys Problems Are Created Equal appeared first on Towards Data Science. Read More

Versioning and Testing Data Solutions: Applying CI and Unit Tests on Interview-style QueriesKDnuggets Learn how to apply unit testing, version control, and continuous integration to data analysis scripts using Python and GitHub Actions.
Learn how to apply unit testing, version control, and continuous integration to data analysis scripts using Python and GitHub Actions. Read More
Harness engineering: leveraging Codex in an agent-first worldOpenAI News By Ryan Lopopolo, Member of the Technical Staff
By Ryan Lopopolo, Member of the Technical Staff Read More
Barclays bets on AI to cut costs and boost returnsAI News Barclays recorded a 12 % jump in annual profit for 2025, reporting £9.1 billion in earnings before tax, up from £8.1 billion a year earlier. The bank also raised its performance targets out through 2028, aiming for a return on tangible equity (RoTE) of more than 14 %, up from a previous goal of above
The post Barclays bets on AI to cut costs and boost returns appeared first on AI News.
Barclays recorded a 12 % jump in annual profit for 2025, reporting £9.1 billion in earnings before tax, up from £8.1 billion a year earlier. The bank also raised its performance targets out through 2028, aiming for a return on tangible equity (RoTE) of more than 14 %, up from a previous goal of above
The post Barclays bets on AI to cut costs and boost returns appeared first on AI News. Read More

How insurance leaders use agentic AI to cut operational costsAI News Agentic AI offers insurance leaders a path to scalable efficiency as the sector confronts a tough digital transformation. Insurers hold deep data reserves and employ a workforce skilled in analytic decision-making. Despite these advantages, the industry has largely failed to advance beyond pilot programmes. Research suggests only seven percent of insurers have scaled these initiatives
The post How insurance leaders use agentic AI to cut operational costs appeared first on AI News.
Agentic AI offers insurance leaders a path to scalable efficiency as the sector confronts a tough digital transformation. Insurers hold deep data reserves and employ a workforce skilled in analytic decision-making. Despite these advantages, the industry has largely failed to advance beyond pilot programmes. Research suggests only seven percent of insurers have scaled these initiatives
The post How insurance leaders use agentic AI to cut operational costs appeared first on AI News. Read More
Red Hat unifies AI and tactical edge deployment for UK MODAI News The UK Ministry of Defence (MOD) has selected Red Hat to architect a unified AI and hybrid cloud backbone across its entire estate. Announced today, the agreement is designed to break down data silos and accelerate the deployment of AI models from the data centre to the tactical edge. For CIOs, it’s part of a
The post Red Hat unifies AI and tactical edge deployment for UK MOD appeared first on AI News.
The UK Ministry of Defence (MOD) has selected Red Hat to architect a unified AI and hybrid cloud backbone across its entire estate. Announced today, the agreement is designed to break down data silos and accelerate the deployment of AI models from the data centre to the tactical edge. For CIOs, it’s part of a
The post Red Hat unifies AI and tactical edge deployment for UK MOD appeared first on AI News. Read More