
Debenhams pilots agentic AI commerce via PayPal integrationAI News Debenhams is piloting agentic AI commerce via PayPal integration to reduce mobile friction and help solve a familiar problem for retailers. Mobile checkout abandonment remains a persistent revenue leak for digital retailers. Debenhams Group is attempting to close this gap by deploying an agentic AI interface within the PayPal app. The pilot makes Debenhams the
The post Debenhams pilots agentic AI commerce via PayPal integration appeared first on AI News.
Debenhams is piloting agentic AI commerce via PayPal integration to reduce mobile friction and help solve a familiar problem for retailers. Mobile checkout abandonment remains a persistent revenue leak for digital retailers. Debenhams Group is attempting to close this gap by deploying an agentic AI interface within the PayPal app. The pilot makes Debenhams the
The post Debenhams pilots agentic AI commerce via PayPal integration appeared first on AI News. Read More

Exploring AI-Augmented Sensemaking of Patient-Generated Health Data: A Mixed-Method Study with Healthcare Professionals in Cardiac Risk Reductioncs.AI updates on arXiv.org arXiv:2602.05687v4 Announce Type: replace-cross
Abstract: Individuals are increasingly generating substantial personal health and lifestyle data, e.g. through wearables and smartphones. While such data could transform preventative care, its integration into clinical practice is hindered by its scale, heterogeneity and the time pressure and data literacy of healthcare professionals (HCPs). We explore how large language models (LLMs) can support sensemaking of patient-generated health data (PGHD) with automated summaries and natural language data exploration. Using cardiovascular disease (CVD) risk reduction as a use case, 16 HCPs reviewed multimodal PGHD in a mixed-methods study with a prototype that integrated common charts, LLM-generated summaries, and a conversational interface. Findings show that AI summaries provided quick overviews that anchored exploration, while conversational interaction supported flexible analysis and bridged data-literacy gaps. However, HCPs raised concerns about transparency, privacy, and overreliance. We contribute empirical insights and sociotechnical design implications for integrating AI-driven summarization and conversation into clinical workflows to support PGHD sensemaking.
arXiv:2602.05687v4 Announce Type: replace-cross
Abstract: Individuals are increasingly generating substantial personal health and lifestyle data, e.g. through wearables and smartphones. While such data could transform preventative care, its integration into clinical practice is hindered by its scale, heterogeneity and the time pressure and data literacy of healthcare professionals (HCPs). We explore how large language models (LLMs) can support sensemaking of patient-generated health data (PGHD) with automated summaries and natural language data exploration. Using cardiovascular disease (CVD) risk reduction as a use case, 16 HCPs reviewed multimodal PGHD in a mixed-methods study with a prototype that integrated common charts, LLM-generated summaries, and a conversational interface. Findings show that AI summaries provided quick overviews that anchored exploration, while conversational interaction supported flexible analysis and bridged data-literacy gaps. However, HCPs raised concerns about transparency, privacy, and overreliance. We contribute empirical insights and sociotechnical design implications for integrating AI-driven summarization and conversation into clinical workflows to support PGHD sensemaking. Read More
A Coding Implementation to Design a Stateful Tutor Agent with Long-Term Memory, Semantic Recall, and Adaptive Practice GenerationMarkTechPost In this tutorial, we build a fully stateful personal tutor agent that moves beyond short-lived chat interactions and learns continuously over time. We design the system to persist user preferences, track weak learning areas, and selectively recall only relevant past context when responding. By combining durable storage, semantic retrieval, and adaptive prompting, we demonstrate how
The post A Coding Implementation to Design a Stateful Tutor Agent with Long-Term Memory, Semantic Recall, and Adaptive Practice Generation appeared first on MarkTechPost.
In this tutorial, we build a fully stateful personal tutor agent that moves beyond short-lived chat interactions and learns continuously over time. We design the system to persist user preferences, track weak learning areas, and selectively recall only relevant past context when responding. By combining durable storage, semantic retrieval, and adaptive prompting, we demonstrate how
The post A Coding Implementation to Design a Stateful Tutor Agent with Long-Term Memory, Semantic Recall, and Adaptive Practice Generation appeared first on MarkTechPost. Read More
Google DeepMind Proposes New Framework for Intelligent AI Delegation to Secure the Emerging Agentic Web for Future EconomiesMarkTechPost The AI industry is currently obsessed with ‘agents’—autonomous programs that do more than just chat. However, most current multi-agent systems rely on brittle, hard-coded heuristics that fail when the environment changes. Google DeepMind researchers have proposed a new solution. The research team argued that for the ‘agentic web’ to scale, agents must move beyond simple
The post Google DeepMind Proposes New Framework for Intelligent AI Delegation to Secure the Emerging Agentic Web for Future Economies appeared first on MarkTechPost.
The AI industry is currently obsessed with ‘agents’—autonomous programs that do more than just chat. However, most current multi-agent systems rely on brittle, hard-coded heuristics that fail when the environment changes. Google DeepMind researchers have proposed a new solution. The research team argued that for the ‘agentic web’ to scale, agents must move beyond simple
The post Google DeepMind Proposes New Framework for Intelligent AI Delegation to Secure the Emerging Agentic Web for Future Economies appeared first on MarkTechPost. Read More

AI isn’t just changing how we work and hallucinating every 3rd query. It’s rewriting the economics of entire industries. Industries most exposed to AI have experienced revenue per employee growing nearly 3× faster since 2022 than less-AI-exposed industries (McKinsey – Superagency in the workplace). Wages in these sectors are rising twice as quickly (McKinsey – […]

The AI Impact Revolution The AI transformation isn’t coming. It’s happening right now, reshaping careers, companies, and entire economies at unprecedented speed. While headlines focus on job displacement fears, the data reveals a more complex story of profound opportunity for those who understand what’s actually changing. The numbers don’t lie. Workers with AI skills earn […]
Meet ‘Kani-TTS-2’: A 400M Param Open Source Text-to-Speech Model that Runs in 3GB VRAM with Voice Cloning SupportMarkTechPost The landscape of generative audio is shifting toward efficiency. A new open-source contender, Kani-TTS-2, has been released by the team at nineninesix.ai. This model marks a departure from heavy, compute-expensive TTS systems. Instead, it treats audio as a language, delivering high-fidelity speech synthesis with a remarkably small footprint. Kani-TTS-2 offers a lean, high-performance alternative to
The post Meet ‘Kani-TTS-2’: A 400M Param Open Source Text-to-Speech Model that Runs in 3GB VRAM with Voice Cloning Support appeared first on MarkTechPost.
The landscape of generative audio is shifting toward efficiency. A new open-source contender, Kani-TTS-2, has been released by the team at nineninesix.ai. This model marks a departure from heavy, compute-expensive TTS systems. Instead, it treats audio as a language, delivering high-fidelity speech synthesis with a remarkably small footprint. Kani-TTS-2 offers a lean, high-performance alternative to
The post Meet ‘Kani-TTS-2’: A 400M Param Open Source Text-to-Speech Model that Runs in 3GB VRAM with Voice Cloning Support appeared first on MarkTechPost. Read More
A beginner’s guide to Tmux: a multitasking superpower for your terminalTowards Data Science One of the new things I’ve come across recently, while researching command-line-based coding assistants, is the mention and use of a tool I hadn’t heard of before. That tool is called Tmux, which stands for Terminal Multiplexer. In the simplest possible terms, Tmux allows you to split up a single terminal window into a number
The post A beginner’s guide to Tmux: a multitasking superpower for your terminal appeared first on Towards Data Science.
One of the new things I’ve come across recently, while researching command-line-based coding assistants, is the mention and use of a tool I hadn’t heard of before. That tool is called Tmux, which stands for Terminal Multiplexer. In the simplest possible terms, Tmux allows you to split up a single terminal window into a number
The post A beginner’s guide to Tmux: a multitasking superpower for your terminal appeared first on Towards Data Science. Read More
Moonshot AI Launches Kimi Claw: Native OpenClaw on Kimi.com with 5,000 Community Skills and 40GB Cloud Storage NowMarkTechPost Moonshot AI has officially brought the power of OpenClaw framework directly to the browser. The newly rebranded Kimi Claw is now native to kimi.com, providing developers and data scientists with a persistent, 24/7 AI agent environment. This update moves the project from a local setup to a cloud-native powerhouse. This means the infrastructure for complex
The post Moonshot AI Launches Kimi Claw: Native OpenClaw on Kimi.com with 5,000 Community Skills and 40GB Cloud Storage Now appeared first on MarkTechPost.
Moonshot AI has officially brought the power of OpenClaw framework directly to the browser. The newly rebranded Kimi Claw is now native to kimi.com, providing developers and data scientists with a persistent, 24/7 AI agent environment. This update moves the project from a local setup to a cloud-native powerhouse. This means the infrastructure for complex
The post Moonshot AI Launches Kimi Claw: Native OpenClaw on Kimi.com with 5,000 Community Skills and 40GB Cloud Storage Now appeared first on MarkTechPost. Read More
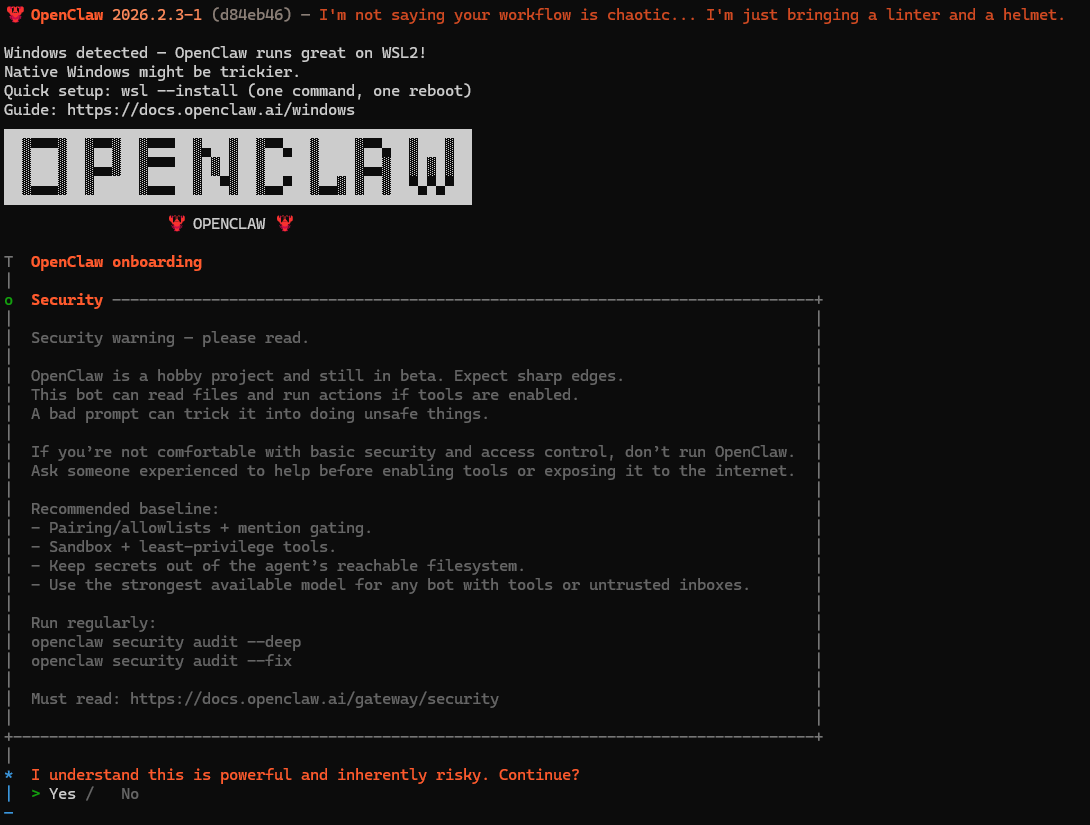
Getting Started with OpenClaw and Connecting It with WhatsAppMarkTechPost OpenClaw is a self-hosted personal AI assistant that runs on your own devices and communicates through the apps you already use—such as WhatsApp, Telegram, Slack, Discord, and more. It can answer questions, automate tasks, interact with your files and services, and even speak or listen on supported devices, all while keeping you in control of
The post Getting Started with OpenClaw and Connecting It with WhatsApp appeared first on MarkTechPost.
OpenClaw is a self-hosted personal AI assistant that runs on your own devices and communicates through the apps you already use—such as WhatsApp, Telegram, Slack, Discord, and more. It can answer questions, automate tasks, interact with your files and services, and even speak or listen on supported devices, all while keeping you in control of
The post Getting Started with OpenClaw and Connecting It with WhatsApp appeared first on MarkTechPost. Read More