
A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026Sebastian Raschka, PhD A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026 Read More
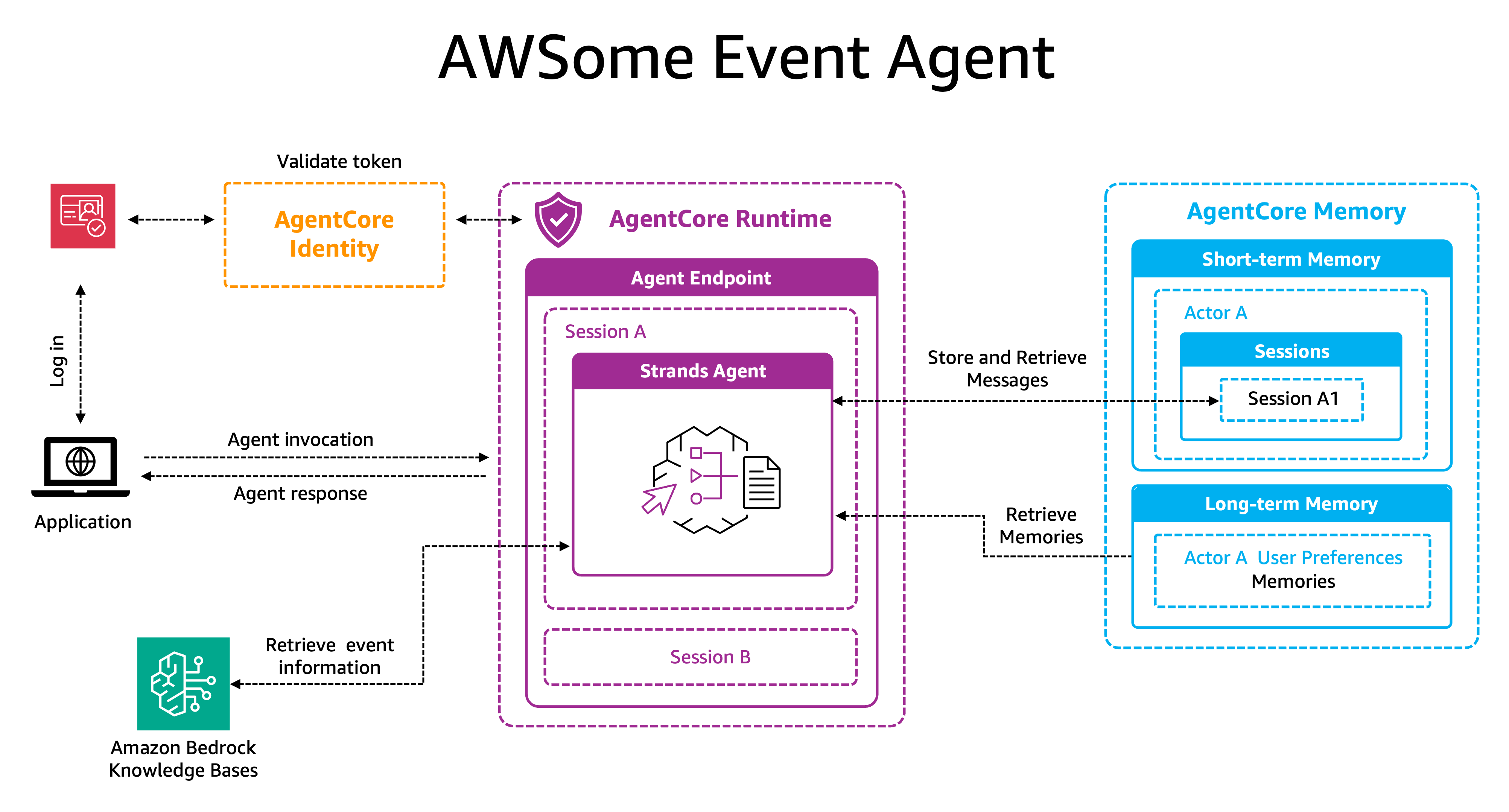
Building intelligent event agents using Amazon Bedrock AgentCore and Amazon Bedrock Knowledge BasesArtificial Intelligence This post demonstrates how to quickly deploy a production-ready event assistant using the components of Amazon Bedrock AgentCore. We’ll build an intelligent companion that remembers attendee preferences and builds personalized experiences over time, while Amazon Bedrock AgentCore handles the heavy lifting of production deployment: Amazon Bedrock AgentCore Memory for maintaining both conversation context and long-term preferences without custom storage solutions, Amazon Bedrock AgentCore Identity for secure multi-IDP authentication, and Amazon Bedrock AgentCore Runtime for serverless scaling and session isolation. We will also use Amazon Bedrock Knowledge Bases for managed RAG and event data retrieval.
This post demonstrates how to quickly deploy a production-ready event assistant using the components of Amazon Bedrock AgentCore. We’ll build an intelligent companion that remembers attendee preferences and builds personalized experiences over time, while Amazon Bedrock AgentCore handles the heavy lifting of production deployment: Amazon Bedrock AgentCore Memory for maintaining both conversation context and long-term preferences without custom storage solutions, Amazon Bedrock AgentCore Identity for secure multi-IDP authentication, and Amazon Bedrock AgentCore Runtime for serverless scaling and session isolation. We will also use Amazon Bedrock Knowledge Bases for managed RAG and event data retrieval. Read More
Breaking the Host Memory Bottleneck: How Peer Direct Transformed Gaudi’s Cloud PerformanceTowards Data Science Engineering RDMA-like performance over cloud host NICs using libfabric, DMA-BUF, and HCCL to restore distributed training scalability
The post Breaking the Host Memory Bottleneck: How Peer Direct Transformed Gaudi’s Cloud Performance appeared first on Towards Data Science.
Engineering RDMA-like performance over cloud host NICs using libfabric, DMA-BUF, and HCCL to restore distributed training scalability
The post Breaking the Host Memory Bottleneck: How Peer Direct Transformed Gaudi’s Cloud Performance appeared first on Towards Data Science. Read More

Role Intelligence AI Model Validator — At a Glance SR 11-7 (Federal Reserve) GARP FRM Tech Jacks 20-Role Table 60-Posting Doc C Analysis AI Model Validator ▲ Very High Demand AI Model Validators independently assess AI/ML models for accuracy, bias, and regulatory compliance. The most technically quantitative role in the AI governance ecosystem, concentrated in […]

Role Intelligence AI Governance Lead — At a Glance IAPP Salary Survey 2025–26 Axial Search AI Governance Jobs 2026 Bloomberg LP AI Governance Posting 20-Role Taxonomy Master Table AI Governance Lead ▲ HIGH DEMAND AI Governance Leads operationalize enterprise AI governance programs, bridging strategy and execution. This role translates director-level strategy into functioning frameworks, day-to-day […]

Role Intelligence AI Auditor — At a Glance IAPP Salary Survey 2025–26 ISACA AAIA Certification Program ForHumanity Independent Audit 20-Role Taxonomy Master Table AI Auditor ▲ HIGH DEMAND AI Auditors provide independent assurance that AI governance controls actually work—testing systems against frameworks like NIST AI RMF and ISO 42001. The accountability mechanism within the AI […]
ActionEngine: From Reactive to Programmatic GUI Agents via State Machine Memorycs.AI updates on arXiv.org arXiv:2602.20502v1 Announce Type: new
Abstract: Existing Graphical User Interface (GUI) agents operate through step-by-step calls to vision language models–taking a screenshot, reasoning about the next action, executing it, then repeating on the new page–resulting in high costs and latency that scale with the number of reasoning steps, and limited accuracy due to no persistent memory of previously visited pages.
We propose ActionEngine, a training-free framework that transitions from reactive execution to programmatic planning through a novel two-agent architecture: a Crawling Agent that constructs an updatable state-machine memory of the GUIs through offline exploration, and an Execution Agent that leverages this memory to synthesize complete, executable Python programs for online task execution.
To ensure robustness against evolving interfaces, execution failures trigger a vision-based re-grounding fallback that repairs the failed action and updates the memory.
This design drastically improves both efficiency and accuracy: on Reddit tasks from the WebArena benchmark, our agent achieves 95% task success with on average a single LLM call, compared to 66% for the strongest vision-only baseline, while reducing cost by 11.8x and end-to-end latency by 2x.
Together, these components yield scalable and reliable GUI interaction by combining global programmatic planning, crawler-validated action templates, and node-level execution with localized validation and repair.
arXiv:2602.20502v1 Announce Type: new
Abstract: Existing Graphical User Interface (GUI) agents operate through step-by-step calls to vision language models–taking a screenshot, reasoning about the next action, executing it, then repeating on the new page–resulting in high costs and latency that scale with the number of reasoning steps, and limited accuracy due to no persistent memory of previously visited pages.
We propose ActionEngine, a training-free framework that transitions from reactive execution to programmatic planning through a novel two-agent architecture: a Crawling Agent that constructs an updatable state-machine memory of the GUIs through offline exploration, and an Execution Agent that leverages this memory to synthesize complete, executable Python programs for online task execution.
To ensure robustness against evolving interfaces, execution failures trigger a vision-based re-grounding fallback that repairs the failed action and updates the memory.
This design drastically improves both efficiency and accuracy: on Reddit tasks from the WebArena benchmark, our agent achieves 95% task success with on average a single LLM call, compared to 66% for the strongest vision-only baseline, while reducing cost by 11.8x and end-to-end latency by 2x.
Together, these components yield scalable and reliable GUI interaction by combining global programmatic planning, crawler-validated action templates, and node-level execution with localized validation and repair. Read More
Using the Path of Least Resistance to Explain Deep Networkscs.AI updates on arXiv.org arXiv:2502.12108v2 Announce Type: replace-cross
Abstract: Integrated Gradients (IG), a widely used axiomatic path-based attribution method, assigns importance scores to input features by integrating model gradients along a straight path from a baseline to the input. While effective in some cases, we show that straight paths can lead to flawed attributions. In this paper, we identify the cause of these misattributions and propose an alternative approach that equips the input space with a model-induced Riemannian metric (derived from the explained model’s Jacobian) and computes attributions by integrating gradients along geodesics under this metric. We call this method Geodesic Integrated Gradients (GIG). To approximate geodesic paths, we introduce two techniques: a k-Nearest Neighbours-based approach for smaller models and a Stochastic Variational Inference-based method for larger ones. Additionally, we propose a new axiom, No-Cancellation Completeness (NCC), which strengthens completeness by ruling out feature-wise cancellation. We prove that, for path-based attributions under the model-induced metric, NCC holds if and only if the integration path is a geodesic. Through experiments on both synthetic and real-world image classification data, we provide empirical evidence supporting our theoretical analysis and showing that GIG produces more faithful attributions than existing methods, including IG, on the benchmarks considered.
arXiv:2502.12108v2 Announce Type: replace-cross
Abstract: Integrated Gradients (IG), a widely used axiomatic path-based attribution method, assigns importance scores to input features by integrating model gradients along a straight path from a baseline to the input. While effective in some cases, we show that straight paths can lead to flawed attributions. In this paper, we identify the cause of these misattributions and propose an alternative approach that equips the input space with a model-induced Riemannian metric (derived from the explained model’s Jacobian) and computes attributions by integrating gradients along geodesics under this metric. We call this method Geodesic Integrated Gradients (GIG). To approximate geodesic paths, we introduce two techniques: a k-Nearest Neighbours-based approach for smaller models and a Stochastic Variational Inference-based method for larger ones. Additionally, we propose a new axiom, No-Cancellation Completeness (NCC), which strengthens completeness by ruling out feature-wise cancellation. We prove that, for path-based attributions under the model-induced metric, NCC holds if and only if the integration path is a geodesic. Through experiments on both synthetic and real-world image classification data, we provide empirical evidence supporting our theoretical analysis and showing that GIG produces more faithful attributions than existing methods, including IG, on the benchmarks considered. Read More
How to Define the Modeling Scope of an Internal Credit Risk ModelTowards Data Science Dataset construction for Internal Ratings-Based (IRB) Probability of Default (PD) models
The post How to Define the Modeling Scope of an Internal Credit Risk Model appeared first on Towards Data Science.
Dataset construction for Internal Ratings-Based (IRB) Probability of Default (PD) models
The post How to Define the Modeling Scope of an Internal Credit Risk Model appeared first on Towards Data Science. Read More
Nokia and AWS pilot AI automation for real-time 5G network slicingAI News Telecom networks may soon begin adjusting themselves in real time, as operators test systems that allow AI agents to manage traffic and service quality. AI may soon be making operational decisions. This week, Nokia and AWS presented a new network slicing system that uses AI agents to monitor network conditions and adjust resources automatically. The
The post Nokia and AWS pilot AI automation for real-time 5G network slicing appeared first on AI News.
Telecom networks may soon begin adjusting themselves in real time, as operators test systems that allow AI agents to manage traffic and service quality. AI may soon be making operational decisions. This week, Nokia and AWS presented a new network slicing system that uses AI agents to monitor network conditions and adjust resources automatically. The
The post Nokia and AWS pilot AI automation for real-time 5G network slicing appeared first on AI News. Read More