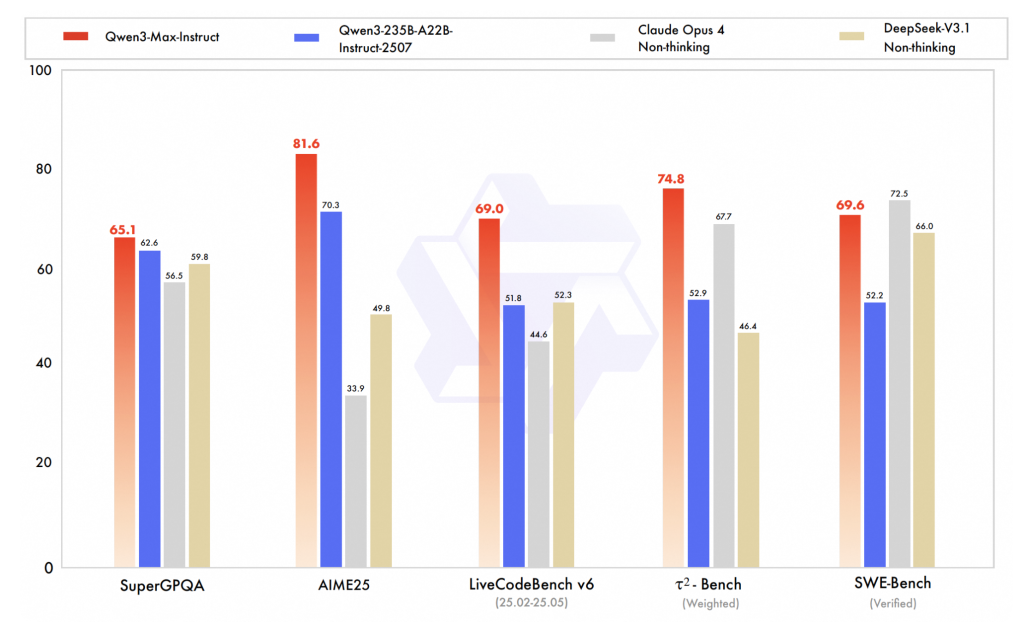
Alibaba has released Qwen3-Max, a trillion-parameter Mixture-of-Experts (MoE) model positioned as its most capable foundation model to date, with an immediate public on-ramp via Qwen Chat and Alibaba Cloud’s Model Studio API. The launch moves Qwen’s 2025 cadence from preview to production and centers on two variants: Qwen3-Max-Instruct for standard reasoning/coding tasks and Qwen3-Max-Thinking for
The post Alibaba’s Qwen3-Max: Production-Ready Thinking Mode, 1T+ Parameters, and Day-One Coding/Agentic Bench Signals appeared first on MarkTechPost. Read More

BC
September 25, 2025The 1T+ parameter scale exceeds what most of us can run locally – even my RTX 3090 with 24GB VRAM would require heavy quantization just for inference, not to mention the “thinking mode” that needs streaming output.
What’s interesting from a local testing point of view is the two-track approach (Instruct vs. Thinking). I’ve been comparing similar patterns with smaller Qwen models on my hardware – the standard instruct models for quick iteration versus the longer-context story models for better quality. The API requirement for incremental_output=true on thinking models indicates significant computational overhead that could make local deployment difficult.
For those of us building LLM testing labs, this highlights the importance of having hardware diversity. While we can’t run Qwen3-Max locally, we can see how these architectural improvements affect the 32B-70B models that actually fit on consumer hardware. The SWE-Bench and Tau2-Bench scores give us reference points to evaluate what we can practically deploy.
It’s worth watching how these MoE optimizations impact the next wave of locally runnable models.