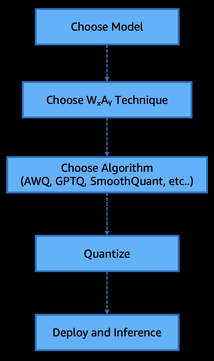
Quantized models can be seamlessly deployed on Amazon SageMaker AI using a few lines of code. In this post, we explore why quantization matters—how it enables lower-cost inference, supports deployment on resource-constrained hardware, and reduces both the financial and environmental impact of modern LLMs, while preserving most of their original performance. We also take a deep dive into the principles behind PTQ and demonstrate how to quantize the model of your choice and deploy it on Amazon SageMaker. Read More
