
UNDERSTANDING AI BIAS
As organizations increasingly rely on Artificial Intelligence (AI) across sectors such as healthcare, hiring, finance, and public safety, understanding and mitigating embedded biases (AI bias) within these systems is vital. Left unaddressed, these biases pose significant threats, including exacerbating systemic discrimination, creating ethical and legal challenges, eroding public trust, and negatively impacting business reputation and operational effectiveness. Doesn’t sound like a very attractive set of problems at all!
Artificial intelligence is already deciding who gets a loan, who hears back from HR, and what headlines buzz your phone. Many of us love the tech, but let’s be honest, it only plays fair if the data, math, and people behind it do as well.
If we skip the guardrails, then you’ll get models that quietly (or not so quietly) tilt toward or against entire groups. Put the right checks in place, and the same algorithms can personalize, declutter, and surface patterns we would never spot on our own. I vote for guardrails and giving people the value that they want (without any shocking or sensational headlines riding shotgun).
So let’s dive in and see what we can dig up. This article will cover:
- What bias actually is. Spoiler: it isn’t our imagination. It’s patterns in the training data, questionable modeling choices, and the occasional bad human assumption.
- How bias sneaks into every layer of your pipeline. From “helpful” demographic proxies to feedback loops that reinforce yesterday’s mistakes.
- Why bias is both a business risk and, weirdly, a feature. When you control it you can tune products for sub-populations, improve accessibility, and boost trust. When you ignore it you invite lawsuits and public relation crash-outs.
- A practical playbook to mitigate—or intentionally harness—bias. We line up controls that map to NIST SP 1270, the EU AI Act, and other gold-standard references, then translate them for teams that don’t speak compliance-ese. Why reinvent the wheel?
Concepts & Key Terms
Concepts:
- Bias in Data: Systemic errors or skews in the collection, labeling, or representation of data that can lead to unfair or inaccurate outcomes in machine learning models.
- Algorithmic Bias: Bias introduced or amplified by the design, assumptions, or implementation of a machine learning algorithm, independent of the data.
- Fairness: The concept of impartiality and justice in the outcomes and impacts of machine learning models, particularly concerning different demographic groups.
- Equity: Ensuring that machine learning systems provide comparable opportunities or outcomes for individuals or groups, often requiring adjustments to address existing inequalities.
- Transparency: The degree to which the workings and decision-making processes of a machine learning model are understandable and explainable to relevant ‘stakeholders” for completeness
- Accountability: The responsibility for the outcomes and impacts of machine learning systems, including the ability to identify who is accountable and to implement corrective measures.
- Representation Bias: A type of bias that occurs when certain groups are under-represented or over-represented in the training data, leading to poor performance for the under-represented groups.
- Measurement Bias: Bias arising from how data is collected, recorded, or used as a proxy, leading to systematic inaccuracies for certain groups.
- Aggregation Bias: Bias that occurs when models are built on aggregated data that obscures important variations or differences within subgroups.
- Evaluation Bias: Bias introduced during the evaluation of machine learning models, such as using metrics that favour certain outcomes or evaluation sets that omit subgroups.
Key Terms:
- Algorithm: A set of rules or instructions that a computer follows to solve a problem or perform a task.
- Artificial Intelligence (AI): The theory and development of computer systems able to perform tasks that normally require human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.
- Machine Learning (ML): A subset of AI that allows computer systems to learn from data without being explicitly programmed.
- Model: The output of a machine learning algorithm that has been trained on data and can be used to make predictions or decisions on new data.
- Training Data: The dataset used to teach a machine learning model to recognize patterns and relationships.
- Protected Characteristics: Attributes of individuals or groups that are legally protected from discrimination, such as race, ethnicity, gender, religion, and disability, age, sexual orientation.
- Demographic Parity: A fairness metric that aims for equal representation of different demographic groups in the outcomes of a machine learning model.
- Equalized Odds: A fairness metric that aims for a model to have equal true positive rates and equal false positive rates across different demographic groups.
- Predictive Parity: A fairness metric that aims for a model to have similar positive predictive values across different demographic groups.
- Proxy Variable: A feature in a dataset that is correlated with a protected characteristic and can unintentionally introduce bias if used in a model.
What Is AI Bias?
AI bias is a systematic, measurable error in an AI system that privileges or disadvantages one outcome, demographic group, or data pattern over another.
NIST groups these errors into three high-level classes:
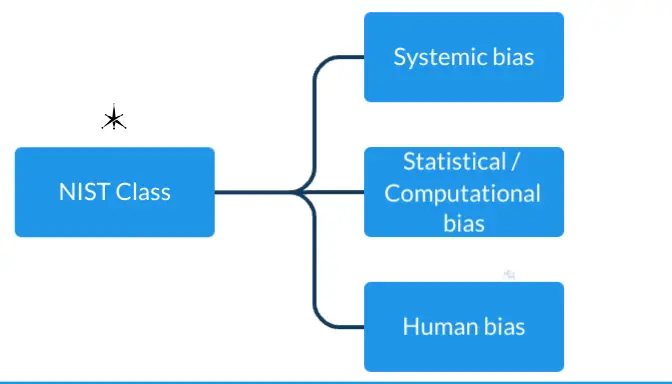
NIST SP 1270 Classes of AI Bias
| NIST Class | Typical Source | Example |
| Systemic bias | Institutional rules or historical patterns baked into data or design | Mortgage-approval models reflecting decades of red-lining |
| Statistical/Computational bias | Non-representative samples, wrong metrics, model over-simplification | Facial-recognition trained mostly on lighter skin tones |
| Human bias | Cognitive shortcuts, confirmation bias, groupthink among designers and users | Product team ignoring edge-case complaints because “the accuracy is good enough” |
These biases can arise at any point in the AI lifecycle during data collection, feature engineering, model design, validation, deployment, or feedback loops.
AI bias is the consistent skew that slithers into an algorithm because of unfair history, lopsided data, math shortcuts or human blind spots. Under NIST you classify and test it; under the EU AI Act you must legally control it; and ISO 42001 tells you to run those controls as an ongoing, auditable business process.
AI bias isn’t a new challenge, though recent scrutiny has elevated it from a niche technical issue to a critical business and societal concern. Historically, instances of bias date back to at least 1988, when a UK medical school’s admissions software inadvertently discriminated against minority applicants, highlighting early that automated systems aren’t immune from prejudice.
However, the 2010s marked a significant turning point, bringing AI bias into public consciousness through several high-profile cases. In 2009, Nikon cameras faced criticism when their image-recognition algorithms repeatedly misidentified Asian users as blinking, underscoring bias embedded within datasets. Shortly thereafter, the COMPAS algorithm, widely used in U.S. criminal courts to predict recidivism risk, sparked controversy by disproportionately flagging Black defendants as high-risk compared to their white counterparts.
A particularly heinous incident occurred in 2015 when Google’s image identification algorithm mistakenly labeled Black users as “gorillas.” This prompted a necessary industry-wide acknowledgment of potential biases inherent in datasets and the risks posed by unchecked algorithmic decision-making. Following closely was Amazon’s 2018 revelation that its AI-powered recruitment tool systematically penalized resumes referencing women or women-focused institutions, stemming from biases in the historically male-dominated training data.
Further illuminating the severity and complexity of AI bias, the landmark “Gender Shades” study by Joy Buolamwini and Timnit Gebru in 2018 demonstrated substantial accuracy disparities in facial recognition systems. These systems performed exceptionally well with light-skinned males but significantly underperformed for darker-skinned females, exposing intersectional biases that previously went unnoticed.
Today, organizations face heightened expectations and regulatory scrutiny, as frameworks such as NIST SP 1270 and the EU AI Act outline critical best practices and compliance requirements. Companies now grapple with balancing innovation against rigorous ethical standards and regulatory expectations.
This evolution underscores a pivotal dilemma: organizations must swiftly innovate to stay competitive while ensuring their AI systems are fair, transparent, and accountable. Companies must navigate these complexities proactively, embedding bias mitigation into their AI development lifecycles to maintain trust, avoid regulatory penalties, and safeguard their reputation in an increasingly vigilant market environment.
This is not an easy problem to resolve. Humans are inherently biased, and our data will reflect this as well. Whether or not AI bias is malicious becomes a moot point when emotional creatures embed their opinions into many repositories of societal data, and this naturally boils to the top as we feed AI our information.


How Does AI Bias Emerge?
“We removed every race and gender column…why are the predictions still unfair?”
“Because bias finds detours,” the data‑scientist says. “Give it one crack and it seeps in somewhere else.”
Artificial‑intelligence systems can absorb bias at every checkpoint of the lifecycle, often invisibly, until the harm shows up in the real world. Below is a guided view of six common gateways, each paired with a true incident, the hidden technical mechanism, the downstream harm and a quick mitigation playbook.
1. Skewed or Missing Data Sampling & Selection bias
Health‑risk tools trained mostly on insured patients underestimated risk for uninsured Black patients, denying them extra care. Such gaps appear whenever source data fail to reflect real‑world diversity: loan‑default models built on salaried workers stumble on gig‑economy borrowers, and language models trained on Western corpora mistranslate Indigenous terms. “Big data” alone does not help; millions of rows that share the same blind spot hard‑code the error. Harm: mis‑allocation of care, credit or safety resources. Mitigate: stratified sampling, synthetic minority oversampling, and batch re‑weighting so each subgroup drives equal gradient updates.
2. Proxy Features
Scrubbing gender does little if the model still reads shopping history or ZIP code. Apple Card potentially gave lower limits to women even though “gender” wasn’t an input. Highly‑correlated latent attributes leak sensitive information through embeddings or decision trees. Harm: hidden discrimination that survives audit. Mitigate: SHAP or counterfactual tests to surface proxies, adversarial de‑biasing, and feature‑engineering checklists that block high‑correlation variables unless fairness metrics stay within tolerance.
3. Label Noise & Measurement Flaws
COMPAS used historical arrest records, already skewed against Black neighborhoods, and labelled Black defendants nearly twice as “high risk” as comparable Whites. Hospitals that code “unknown” for rare diagnoses, or image‑annotation crews that speed through long‑tail categories, inject similar noise. Supervised learning treats labels as ground truth, magnifying error each epoch. Harm: unfair sentencing, missed diagnoses, safety recalls. Mitigate: active learning, human re‑labelling, noise‑robust loss functions and confidence‑based sample re‑weighting.
4. Algorithm & Objective‑Function Choices
Amazon’s résumé‑screening engine optimized accuracy on a decade of male‑heavy hires, so it auto‑downgraded CVs containing “women’s”. Optimizing a single scalar such as cross‑entropy ignores distributional equity; a one‑point accuracy gain can hide a 25‑point minority loss. Harm: disparate error rates, regulatory non‑compliance. Mitigate: fairness‑aware objectives, multi‑objective optimization, calibrated probability adjustment and Pareto‑front hyper‑parameter search.
5. Human Factors Design & Use
Nikon’s blink‑detector rarely saw open eyes on Asian faces because QA teams never tested beyond “typical” Caucasian photos. Humans bring confirmation and anchoring biases into feature selection; end‑users then over‑trust algorithmic output; a phenomenon called automation complacency. Harm: systemic exclusion, silent adoption of bad advice. Mitigate: diverse teams, bias‑awareness training, UX that surfaces uncertainty scores and overrides.
6. Feedback Loops in the Wild
Facebook’s ad engine under-exposed housing ads to multiple protected groups: Black and Hispanic users, women, parents with young children, older adults, and people with disabilities, even when advertisers supplied neutral targets, creating a discriminatory spiral.
YouTube recommendations push fringe content because each click rewards extremity. Predictive-policing sends officers to “hot spots,” produces more arrests, and then “proves” those areas dangerous. Harm: echo chambers, systemic discrimination, regulatory fines. Mitigate: diversity sampling, exploration-exploitation throttles, feedback caps, and scheduled recalibration
A Closer Look at Data‑Driven AI Bias
| Bias Type | What It Means | Everyday Consequence |
| Historical bias | Discrimination embedded in past data | Hiring model sidelines women after decades of male‑dominated CVs |
| Representation bias | Under or over‑sampling groups | Face recognition fails on darker skin tones |
| Measurement bias | Systematic sensor/label error | Smart‑city traffic models favour wealthy districts with newer cameras |
| Exclusion bias | Leaving out critical fields | College‑success model ignores dropout factors |
| Sampling‑strategy bias | Imbalanced mini‑batches during SGD | Minority class gets fewer gradient updates |
| Data‑augmentation bias | Synthetic data magnifies majority patterns | Colour‑jitter tuned on lighter skin amplifies error on darker skin |

List of 40 Biases for Reference
When AI Bias Helps—and When It Hurts
Benefits of managed AI bias

Downsides of unmanaged AI bias
- Legal exposure – Disparate-impact claims in housing, lending, hiring; potential non-compliance with the EU AI Act or U.S. civil-rights laws.
- Reputational damage – Public backlash when AI chatbots produce racist or sexist content.
- Financial cost – Biased fraud-detection that blocks legitimate customers, or underpriced insurance due to hidden correlations, erodes revenue.
- Ethical harm – Reinforcement of historical inequities, loss of trust in AI-augmented services.
Business, Legal and Societal Risks
Poorly managed bias does more than tarnish an algorithm’s accuracy score; it creates real-world liabilities and can erode an organization’s license to operate. Discriminatory outcomes invite class-action lawsuits and regulatory probes.
Regulators are also tightening the screws: the EU AI Act treats missing bias documentation in “high-risk” systems as a finable offense, mirroring the way privacy regulators levy GDPR penalties.
On the operational side, biased perception models in autonomous vehicles or industrial robots can misclassify objects and trigger costly accidents or recalls.
Reputational damage follows close behind; a well-publicised audit showing racial error gaps in a vendor’s system can knock a substantial share of its market value and push enterprise clients to pause renewals.
In short, bias risk spans courtrooms, compliance desks, engineering war rooms, and investor sentiment, underscoring why leadership must treat fairness controls as a core business safeguard, not an optional ethical add-on.
| Risk Category | Sample Consequence |
| Discrimination & civil-rights litigation | Credit-scoring model gives women lower limits → regulator investigation |
| Regulatory non-compliance | High-risk AI system lacks bias documentation → fines under EU AI Act (Art.71) |
| Operational failure | Self-driving car misclassifies dark-colored trucks; accident liabilities |
| Brand & investor trust | Stock dips after facial-recognition vendor flagged for racial error rates 20–34 pp higher on dark-skinned women |
Toolbox for Detecting and Mitigating Bias
As we continue exploring the many ways bias can creep into an AI pipeline, we find that it can surface at each stage. When data is ingested, when models are tuned, when outputs are calibrated, and even months after deployment as real-world feedback drifts.
To help newcomers, the next section summarizes a set of widely used techniques that practitioners can apply at those stages. It starts with exploratory dashboards that reveal class imbalance before any code is shipped, moves to in-process debiasing layers that incorporate fairness into the loss function, lists post-processing methods that close remaining error gaps, and ends with production monitors that flag parity issues as they arise. Each technique lines up with the point in the lifecycle where the corresponding risk typically appears: data-centric tools during ingestion, model-agnostic probes during training and validation, governance checkpoints before release, and drift dashboards once the system is live.
The table that follows presents these lifecycle stages alongside example tools you might adopt, offering a practical starting point rather than a one-size-fits-all prescription:
| Stage | Key Tools / Techniques | Why It Matters (and What Breaks if Omitted) |
|---|---|---|
| Exploratory data analysis | Pandas Profiling · Evidently “Data Drift” report · AIF360 metrics module | Quantifies class imbalance, missing-value patterns and distribution drift before modeling; otherwise you optimize on a skewed sample and bake the bias in. |
| Model-agnostic inspection | Fairlearn dashboard · Google What-If Tool · SHAP / LIME (for proxy-feature discovery) | Slice-level error and counterfactual probes expose hidden proxies; without this, a variable like ZIP code can silently stand in for race or income. |
| Algorithmic debiasing (in-process) | Re-weighting · Adversarial training · Prejudice-remover regularizer · Fairness-constrained loss (DemParity, EqOdds) | Injects fairness during optimization; skipping forces you to choose between raw accuracy and equity later, when it’s costlier to fix. |
| Post-processing | Threshold/reject-option classification · Equalized-odds calibration · ROC subgroup tuning | Calibrates outputs on held-out data to satisfy legal or policy parity metrics; without it, last-mile bias can slip into production. |
| Documentation | Data Sheets · Model Cards · Risk Cards · Impact Assessments (EU AI Act Art. 29a) | Captures provenance, metrics and open questions; auditors and regulators assume “not documented” means “not done.” |
| Continuous monitoring | Evidently AI drift dashboards · Fairlearn metric_frame for live disparity metrics · Concept-drift tests | Watches for bias re-emerging in real-time; failure lets performance decay unnoticed and can trigger compliance breaches. |
| Governance gateways | NIST SP 1270 TEVV checkpoints · ISO/IEC 42001 §9.2 internal audit · Rotating red-team review | Enforces independent sign-off; prevents launch of models with undiscovered bias or poor explainability. |
Tip for small teams: You can chain open-source libraries—Pandas Profiling → Fairlearn → Evidently AI—to cover most bias metrics without expensive enterprise tooling.
Process Controls for AI Developers
Designing an unbiased model takes more than good code; it requires a structured set of guardrails that follow the system from the first idea to the final line of production logs. The checklist below distills those guardrails into practical actions a development team can weave into its normal workflow, aligning with leading standards such as the NIST AI Risk Management Framework and the EU AI Act. Each step answers a simple question: What control keeps bias in check at this point in the lifecycle, and who owns it? By treating the items as routine process checkpoints rather than one-off tasks, teams can catch unfair patterns early, document what they did about them, and monitor for new issues after launch.
- Map use-case risk. Tie each AI project to a risk tier (e.g., NIST AI RMF or EU AI Act “high-risk”) so governance investment matches impact.
- Bias register & taxonomy. Maintain a living spreadsheet keyed to NIST bias terms; log which types were found, mitigated, or accepted with rationale.
- Diverse data and design teams. Research shows heterogeneous teams catch problem labels & proxies earlier.
- Document everything. Publish Data Sheets and Model Cards with:
- Objective, owners, training-data sources
- Fairness metrics per sensitive attribute
- Evaluation protocol and limitations
- Independent review. Implement “red-team” bias audits before deployment; rotate auditors to reduce groupthink.
- Human-in-the-loop safeguards. Provide override controls and clear explanations so impacted users can contest decisions.
- Post-production vigilance. Log model outputs, re-score fairness KPIs, and trigger retraining or rollback when thresholds break.

Due-Diligence Steps for AI Buyers & Users
When you consume AI from a SaaS vendor or API, you inherit its AI bias risk. Use this checklist before signing the contract:
Bonus tip: Run your own AI bias tests on a sandbox API using synthetic profiles (different races, genders, disabilities) to verify the vendor’s claims.
Key Takeaways
- AI bias is not just bad data; it can originate from algorithms, goals, or human heuristics.
- Some biases, like personalization or regulatory fairness adjustments, add value when consciously applied.
- NIST SP 1270’s taxonomy (Systemic, Statistical/Computational, Human) is the leading structure for cataloging and mitigating bias.
- Combine tools (Fairlearn, What-If, AIF360) with process (Model Cards, independent audits, human oversight) for end-to-end control.
- Developers must log, test and monitor bias; buyers must demand documentation and run their own checks.
- Governance is ongoing: models drift, data evolves, and new bias surfaces. Sustainable AI requires continuous vigilance.
Ready to Test Your Knowledge?
References
- NIST. Towards a Standard for Identifying and Managing Bias in Artificial Intelligence (NIST SP 1270), 2022
- Ferrara, E. “Fairness and Bias in Artificial Intelligence: A Brief Survey,” Sci 6 (3), 2024
- NIST SP 1270, Section 3: TEVV Challenges and Guidance
- Ferrara, Table 1 – Generative AI Bias Examples
- Radanliev, P. “AI Ethics: Integrating Transparency, Fairness and Privacy,” Applied AI 39 (1), 2025
- NIST SP 1270 Glossary entries on anchoring, confirmation, automation-complacency, etc.
- Cloud Security Alliance (CSA). AI Model Risk Management Framework (Model Cards, Data Sheets, Risk Cards), 2024
Ready to act?
Start by downloading NIST SP 1270, map the biases most relevant to your use case, and pilot an open-source fairness toolkit on one model. Even a modest audit can uncover hidden risks, and spark the cultural shift toward responsible, trusted AI.
We hope this article covering aspects of AI bias has been helpful. We will update and ensure it stays relevant over time. Please check out our other articles and services on the website!
Please comment and share and like it if it had any value.
We appreciate and benefit from that support greatly!