

CGBench: Benchmarking Language Model Scientific Reasoning for Clinical Genetics Researchcs.AI updates on arXiv.org arXiv:2510.11985v1 Announce Type: new
Abstract: Variant and gene interpretation are fundamental to personalized medicine and translational biomedicine. However, traditional approaches are manual and labor-intensive. Generative language models (LMs) can facilitate this process, accelerating the translation of fundamental research into clinically-actionable insights. While existing benchmarks have attempted to quantify the capabilities of LMs for interpreting scientific data, these studies focus on narrow tasks that do not translate to real-world research. To meet these challenges, we introduce CGBench, a robust benchmark that tests reasoning capabilities of LMs on scientific publications. CGBench is built from ClinGen, a resource of expert-curated literature interpretations in clinical genetics. CGBench measures the ability to 1) extract relevant experimental results following precise protocols and guidelines, 2) judge the strength of evidence, and 3) categorize and describe the relevant outcome of experiments. We test 8 different LMs and find that while models show promise, substantial gaps exist in literature interpretation, especially on fine-grained instructions. Reasoning models excel in fine-grained tasks but non-reasoning models are better at high-level interpretations. Finally, we measure LM explanations against human explanations with an LM judge approach, revealing that models often hallucinate or misinterpret results even when correctly classifying evidence. CGBench reveals strengths and weaknesses of LMs for precise interpretation of scientific publications, opening avenues for future research in AI for clinical genetics and science more broadly.
arXiv:2510.11985v1 Announce Type: new
Abstract: Variant and gene interpretation are fundamental to personalized medicine and translational biomedicine. However, traditional approaches are manual and labor-intensive. Generative language models (LMs) can facilitate this process, accelerating the translation of fundamental research into clinically-actionable insights. While existing benchmarks have attempted to quantify the capabilities of LMs for interpreting scientific data, these studies focus on narrow tasks that do not translate to real-world research. To meet these challenges, we introduce CGBench, a robust benchmark that tests reasoning capabilities of LMs on scientific publications. CGBench is built from ClinGen, a resource of expert-curated literature interpretations in clinical genetics. CGBench measures the ability to 1) extract relevant experimental results following precise protocols and guidelines, 2) judge the strength of evidence, and 3) categorize and describe the relevant outcome of experiments. We test 8 different LMs and find that while models show promise, substantial gaps exist in literature interpretation, especially on fine-grained instructions. Reasoning models excel in fine-grained tasks but non-reasoning models are better at high-level interpretations. Finally, we measure LM explanations against human explanations with an LM judge approach, revealing that models often hallucinate or misinterpret results even when correctly classifying evidence. CGBench reveals strengths and weaknesses of LMs for precise interpretation of scientific publications, opening avenues for future research in AI for clinical genetics and science more broadly. Read More

Salesforce commits $15 billion to boost AI growth in San FranciscoAI News Salesforce plans to invest $15 billion in San Francisco over the next five years to help businesses adopt AI. The move underscores the company’s push to stay competitive as AI becomes central to enterprise software. Founded and headquartered in San Francisco since 1999, Salesforce has been adding AI features across its products, including the workplace
The post Salesforce commits $15 billion to boost AI growth in San Francisco appeared first on AI News.
Salesforce plans to invest $15 billion in San Francisco over the next five years to help businesses adopt AI. The move underscores the company’s push to stay competitive as AI becomes central to enterprise software. Founded and headquartered in San Francisco since 1999, Salesforce has been adding AI features across its products, including the workplace
The post Salesforce commits $15 billion to boost AI growth in San Francisco appeared first on AI News. Read More

Cisco: Only 13% have a solid AI strategy and they’re lapping rivalsAI News If you’ve ever thought companies talk more than act when it comes to their AI strategy, a new Cisco report backs you up. It turns out that just 13 percent globally are actually prepared for the AI revolution. However, this small group – which Cisco calls the ‘Pacesetters’ – are lapping the competition. The third
The post Cisco: Only 13% have a solid AI strategy and they’re lapping rivals appeared first on AI News.
If you’ve ever thought companies talk more than act when it comes to their AI strategy, a new Cisco report backs you up. It turns out that just 13 percent globally are actually prepared for the AI revolution. However, this small group – which Cisco calls the ‘Pacesetters’ – are lapping the competition. The third
The post Cisco: Only 13% have a solid AI strategy and they’re lapping rivals appeared first on AI News. Read More
Building A Successful Relationship With StakeholdersTowards Data Science Show your value by moving beyond the technical
The post Building A Successful Relationship With Stakeholders appeared first on Towards Data Science.
Show your value by moving beyond the technical
The post Building A Successful Relationship With Stakeholders appeared first on Towards Data Science. Read More
Human Won’t Replace PythonTowards Data Science Why vibe-coding is not a step up from “classic” coding — and why it matters
The post Human Won’t Replace Python appeared first on Towards Data Science.
Why vibe-coding is not a step up from “classic” coding — and why it matters
The post Human Won’t Replace Python appeared first on Towards Data Science. Read More
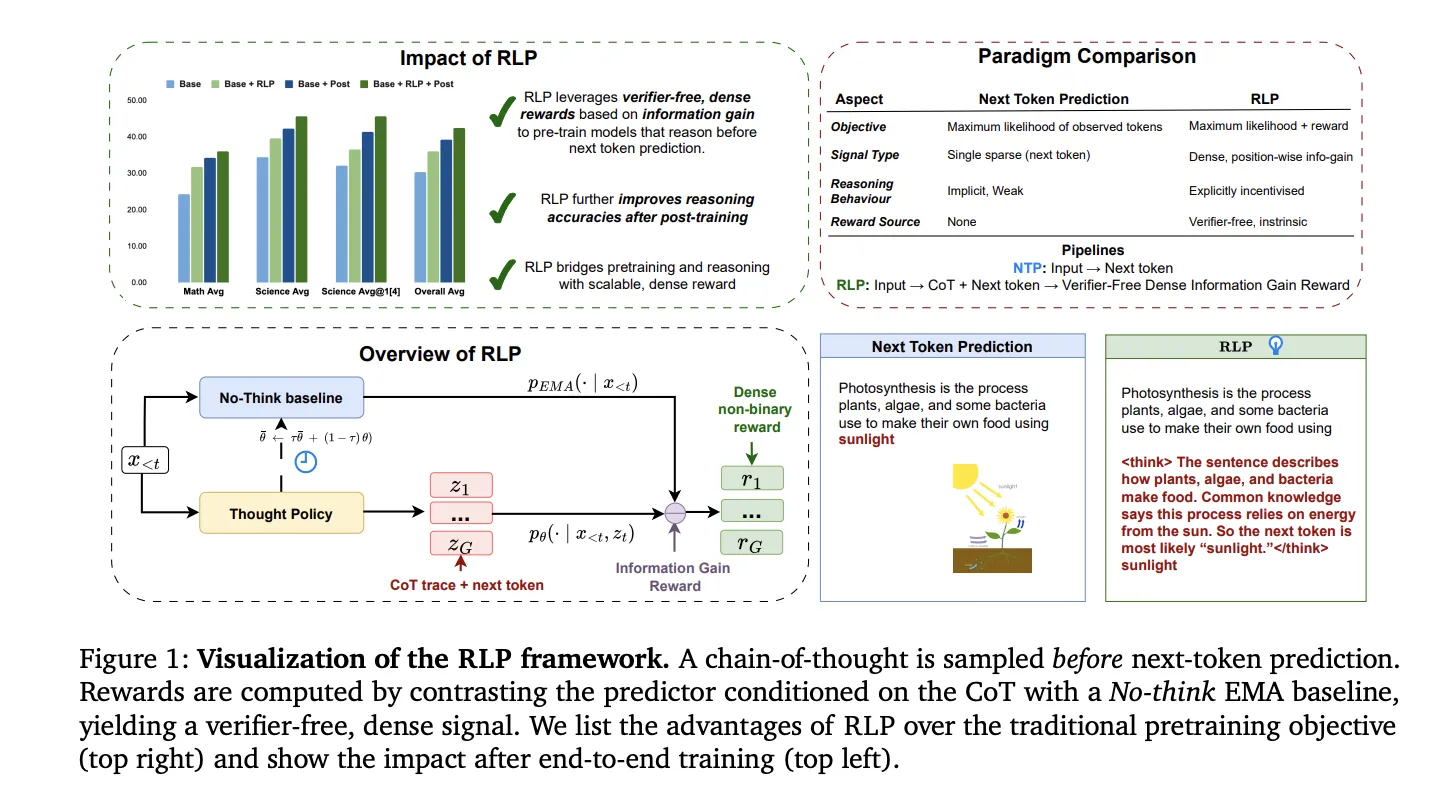
NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During PretrainingMarkTechPost NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather than deferring it to post-training. The core idea is simple and testable: treat a short chain-of-thought (CoT) as an action sampled before next-token prediction and reward it by the information gain it provides on the
The post NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During Pretraining appeared first on MarkTechPost.
NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather than deferring it to post-training. The core idea is simple and testable: treat a short chain-of-thought (CoT) as an action sampled before next-token prediction and reward it by the information gain it provides on the
The post NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During Pretraining appeared first on MarkTechPost. Read More
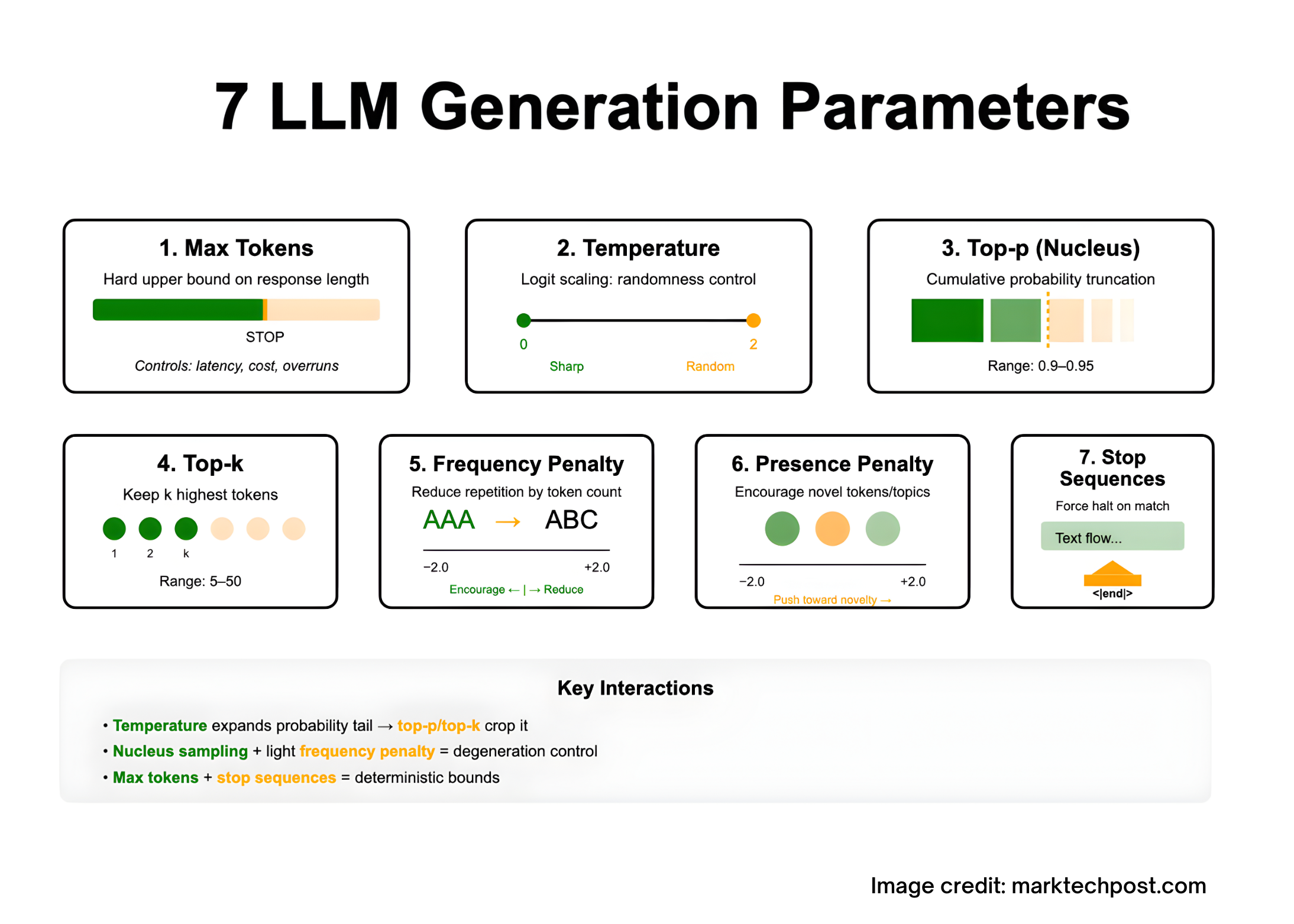
7 LLM Generation Parameters—What They Do and How to Tune Them?MarkTechPost Tuning LLM outputs is largely a decoding problem: you shape the model’s next-token distribution with a handful of sampling controls—max tokens (caps response length under the model’s context limit), temperature (logit scaling for more/less randomness), top-p/nucleus and top-k (truncate the candidate set by probability mass or rank), frequency and presence penalties (discourage repetition or encourage
The post 7 LLM Generation Parameters—What They Do and How to Tune Them? appeared first on MarkTechPost.
Tuning LLM outputs is largely a decoding problem: you shape the model’s next-token distribution with a handful of sampling controls—max tokens (caps response length under the model’s context limit), temperature (logit scaling for more/less randomness), top-p/nucleus and top-k (truncate the candidate set by probability mass or rank), frequency and presence penalties (discourage repetition or encourage
The post 7 LLM Generation Parameters—What They Do and How to Tune Them? appeared first on MarkTechPost. Read More
Scientists build artificial neurons that work like real onesArtificial Intelligence News — ScienceDaily UMass Amherst engineers have built an artificial neuron powered by bacterial protein nanowires that functions like a real one, but at extremely low voltage. This allows for seamless communication with biological cells and drastically improved energy efficiency. The discovery could lead to bio-inspired computers and wearable electronics that no longer need power-hungry amplifiers. Future applications may include sensors powered by sweat or devices that harvest electricity from thin air.
UMass Amherst engineers have built an artificial neuron powered by bacterial protein nanowires that functions like a real one, but at extremely low voltage. This allows for seamless communication with biological cells and drastically improved energy efficiency. The discovery could lead to bio-inspired computers and wearable electronics that no longer need power-hungry amplifiers. Future applications may include sensors powered by sweat or devices that harvest electricity from thin air. Read More
Combo-Gait: Unified Transformer Framework for Multi-Modal Gait Recognition and Attribute Analysiscs.AI updates on arXiv.org arXiv:2510.10417v1 Announce Type: cross
Abstract: Gait recognition is an important biometric for human identification at a distance, particularly under low-resolution or unconstrained environments. Current works typically focus on either 2D representations (e.g., silhouettes and skeletons) or 3D representations (e.g., meshes and SMPLs), but relying on a single modality often fails to capture the full geometric and dynamic complexity of human walking patterns. In this paper, we propose a multi-modal and multi-task framework that combines 2D temporal silhouettes with 3D SMPL features for robust gait analysis. Beyond identification, we introduce a multitask learning strategy that jointly performs gait recognition and human attribute estimation, including age, body mass index (BMI), and gender. A unified transformer is employed to effectively fuse multi-modal gait features and better learn attribute-related representations, while preserving discriminative identity cues. Extensive experiments on the large-scale BRIAR datasets, collected under challenging conditions such as long-range distances (up to 1 km) and extreme pitch angles (up to 50{deg}), demonstrate that our approach outperforms state-of-the-art methods in gait recognition and provides accurate human attribute estimation. These results highlight the promise of multi-modal and multitask learning for advancing gait-based human understanding in real-world scenarios.
arXiv:2510.10417v1 Announce Type: cross
Abstract: Gait recognition is an important biometric for human identification at a distance, particularly under low-resolution or unconstrained environments. Current works typically focus on either 2D representations (e.g., silhouettes and skeletons) or 3D representations (e.g., meshes and SMPLs), but relying on a single modality often fails to capture the full geometric and dynamic complexity of human walking patterns. In this paper, we propose a multi-modal and multi-task framework that combines 2D temporal silhouettes with 3D SMPL features for robust gait analysis. Beyond identification, we introduce a multitask learning strategy that jointly performs gait recognition and human attribute estimation, including age, body mass index (BMI), and gender. A unified transformer is employed to effectively fuse multi-modal gait features and better learn attribute-related representations, while preserving discriminative identity cues. Extensive experiments on the large-scale BRIAR datasets, collected under challenging conditions such as long-range distances (up to 1 km) and extreme pitch angles (up to 50{deg}), demonstrate that our approach outperforms state-of-the-art methods in gait recognition and provides accurate human attribute estimation. These results highlight the promise of multi-modal and multitask learning for advancing gait-based human understanding in real-world scenarios. Read More
SASER: Stego attacks on open-source LLMscs.AI updates on arXiv.org arXiv:2510.10486v1 Announce Type: cross
Abstract: Open-source large language models (LLMs) have demonstrated considerable dominance over proprietary LLMs in resolving neural processing tasks, thanks to the collaborative and sharing nature. Although full access to source codes, model parameters, and training data lays the groundwork for transparency, we argue that such a full-access manner is vulnerable to stego attacks, and their ill-effects are not fully understood. In this paper, we conduct a systematic formalization for stego attacks on open-source LLMs by enumerating all possible threat models associated with adversary objectives, knowledge, and capabilities. Therein, the threat posed by adversaries with internal knowledge, who inject payloads and triggers during the model sharing phase, is of practical interest. We go even further and propose the first stego attack on open-source LLMs, dubbed SASER, which wields impacts through identifying targeted parameters, embedding payloads, injecting triggers, and executing payloads sequentially. Particularly, SASER enhances the attack robustness against quantization-based local deployment by de-quantizing the embedded payloads. In addition, to achieve stealthiness, SASER devises the performance-aware importance metric to identify targeted parameters with the least degradation of model performance. Extensive experiments on LlaMA2-7B and ChatGLM3-6B, without quantization, show that the stealth rate of SASER outperforms existing stego attacks (for general DNNs) by up to 98.1%, while achieving the same attack success rate (ASR) of 100%. More importantly, SASER improves ASR on quantized models from 0 to 100% in all settings. We appeal for investigations on countermeasures against SASER in view of the significant attack effectiveness.
arXiv:2510.10486v1 Announce Type: cross
Abstract: Open-source large language models (LLMs) have demonstrated considerable dominance over proprietary LLMs in resolving neural processing tasks, thanks to the collaborative and sharing nature. Although full access to source codes, model parameters, and training data lays the groundwork for transparency, we argue that such a full-access manner is vulnerable to stego attacks, and their ill-effects are not fully understood. In this paper, we conduct a systematic formalization for stego attacks on open-source LLMs by enumerating all possible threat models associated with adversary objectives, knowledge, and capabilities. Therein, the threat posed by adversaries with internal knowledge, who inject payloads and triggers during the model sharing phase, is of practical interest. We go even further and propose the first stego attack on open-source LLMs, dubbed SASER, which wields impacts through identifying targeted parameters, embedding payloads, injecting triggers, and executing payloads sequentially. Particularly, SASER enhances the attack robustness against quantization-based local deployment by de-quantizing the embedded payloads. In addition, to achieve stealthiness, SASER devises the performance-aware importance metric to identify targeted parameters with the least degradation of model performance. Extensive experiments on LlaMA2-7B and ChatGLM3-6B, without quantization, show that the stealth rate of SASER outperforms existing stego attacks (for general DNNs) by up to 98.1%, while achieving the same attack success rate (ASR) of 100%. More importantly, SASER improves ASR on quantized models from 0 to 100% in all settings. We appeal for investigations on countermeasures against SASER in view of the significant attack effectiveness. Read More
